
Log streaming
Log streaming lets you collect and send configuration audit logs or network flow logs about your Tailscale network (known as a tailnet) into various systems for collection and analysis.
You can use User-Agent: TailscaleLogStreamPublisher to identify Tailscale traffic.
Supported integrations
Tailscale supports different ways of integrating log streaming.
SIEM integrations
You can stream logs into a Security information and event management (SIEM) system to help detect and respond to security threats, set up alerting and monitoring rules, and the like.
We support log streaming integrations for the following SIEM systems:
- Axiom
- Cribl
- Datadog
- Elasticsearch Logstash, through a data stream
- Panther
- Splunk, through an HTTP Event Collector
- Additional SIEM systems
Amazon S3 and S3-compatible services
You can stream your logs to Amazon S3 and S3-compatible services for various cloud storage providers.
We support log streaming integrations for sending logs to the following S3 bucket types:
Other integrations types
Additional integrations that you can use for log streaming include:
Prerequisites
- You need an endpoint and credentials for either your SIEM integration or S3 cloud storage provider. Consult your vendor's documentation for how to get an endpoint and API credentials.
- You need to be an Owner, Admin, Network admin, or IT admin to add, edit, and delete a streaming destination.
Configuration log streaming
Add configuration log streaming
- Open the Configuration logs page of the admin console.
- Select Start streaming.
- In the Start streaming configuration logs dialog, enter the following information:
-
Select a destination: Select the AWS | S3 radio button.
-
Sub-destinations: Select the Amazon S3 radio button.
-
Region: Enter AWS region where S3 bucket is located. For a list of available AWS regions, refer to AWS service endpoints.
-
Bucket: Enter the S3 bucket name where you want to upload logs.
-
Compression: Select
none,zstd, orgzip. The default compression method iszstd. -
Upload period: Enter how often to upload new objects, specified in minutes. Take into consideration latency and bandwidth. The default period is 1 minute and the range you can use is between 1 minute and 24 hours.
-
(Optional) Object key prefix : Enter the S3 object key to prefix for the file name string. For example, a prefix of
audit-logs/will produce S3 object keys similar toaudit-logs/2024/04/22/12:34:56.json. This lets you upload both audit and network logs to the same S3 bucket, with the ability to separate the data. -
Role ARN: Enter the Amazon Resource Name (ARN). This grants your tailnet access to write to your S3 bucket. For more details, refer to Access to AWS accounts owned by third parties.
-
Required IAM trust policy: Copy and edit the generated details into an existing AWS role trust policy or create a new trust policy from the AWS IAM console. The provided
PrincipalandConditionstring values are unique to your integration and must be added as displayed.The following is an example of a trust policy showing you where to add these details and the formatting to use.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "891612552178" }, "Condition": { "StringEquals": { "sts:ExternalId": "69f73fe7-cfcc-414e-8d45-35eb5d70fe7d" } }, "Action": "sts:AssumeRole" } ] } -
Add an AWS role permission policy from the AWS IAM console to allow objects to be sent to your S3 bucket.
The following is an example of a permission policy showing you where to add these details and the formatting to use.
{ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Action": [ "s3:PutObject" ], "Resource": "arn:aws:s3:::yourBucketName/*" } } -
In the Start streaming configuration logs dialog of the admin console, select Start streaming.
-
- Check your S3 monitoring tools to verify you are successfully streaming configuration audit logs from your tailnet to your S3 bucket.
Depending on network conditions, there may be a delay before you can see the log streaming appear in your third-party tools.
Edit a configuration log streaming destination
You can change the information for passing your logs to your preferred streaming destination.
- Open the Configuration logs page of the admin console.
- For the system that you want to update, select the Action dropdown, then select Edit.
- Update the values as needed.
- Select Save changes.
If you are editing a log streaming destination for an Amazon S3 bucket, you can update the Role ARN field (the Amazon resource name) if the resource name already belongs to the specified AWS account. If the role does not belong to the AWS account, you must delete the log streaming destination in the admin console and create a new one.
Delete a configuration log streaming destination
- Open the Configuration logs page of the admin console.
- For the integration that you want to delete, select the Action dropdown, then select Delete.
- In the confirmation dialog, select Delete.
Network log streaming
Add a network log streaming destination
- Make sure you have network flow logs enabled for your tailnet.
- Select Start streaming.
- In the Start streaming network logs dialog, enter the following information:
-
Select a destination: Select the AWS | S3 radio button.
-
Sub-destinations: Select the Amazon S3 radio button.
-
Region: Enter AWS region where S3 bucket is located. For a list of available AWS regions, refer to AWS service endpoints.
-
Bucket: Enter the S3 bucket name where you want to upload logs.
-
Compression: From the drop-down menu, select
none,zstd, orgzip. The default compression iszstd. -
Upload period: Enter how often to upload new objects, specified in minutes. Take into consideration latency and bandwidth. The default period is 1 minute and the range you can use is between 1 minute and 24 hours.
-
(Optional) Object key prefix : Enter the S3 object key to prefix for the file name string. For example, a prefix of
audit-logs/will produce S3 object keys similar toaudit-logs/2024/04/22/12:34:56.json. This lets you upload both audit and network logs to the same S3 bucket, with the ability to separate the data. -
Role ARN: Enter the Amazon Resource Name (ARN). This grants your tailnet access to write to your S3 bucket. For more details, refer to Access to AWS accounts owned by third parties.
-
Required IAM trust policy: Copy and edit the generated details into an existing AWS role trust policy or create a new trust policy from the AWS IAM console. The provided
PrincipalandConditionstring values are unique to your integration and must be added as displayed.The following is an example of a trust policy showing you where to add these details and the formatting to use.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "891612552178" }, "Condition": { "StringEquals": { "sts:ExternalId": "69f73fe7-cfcc-414e-8d45-35eb5d70fe7d" } }, "Action": "sts:AssumeRole" } ] } -
Add an AWS role permission policy from the AWS IAM console to allow objects to be sent to your S3 bucket.
The following is an example of a permission policy showing you where to add these details and the formatting to use.
{ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Action": [ "s3:PutObject" ], "Resource": "arn:aws:s3:::yourBucketName/*" } } -
In the Start streaming configuration logs dialog of the admin console, select Start streaming.
-
- Check your S3 monitoring tools to verify you are successfully streaming network flow logs from your tailnet to your S3 bucket.
Depending on network conditions, there may be a delay before you can see the log streaming appear in your third-party tools.
Edit a network log streaming destination
You can change the information for passing your logs to your preferred streaming destination.
- Open the Network flow logs page of the admin console.
- For the system that you want to update, select the Action dropdown, then select Edit.
- Update the values as needed.
- Select Save changes.
If you are editing a log streaming destination for an Amazon S3 bucket, you can update the Role ARN field (the Amazon resource name) if the resource name already belongs to the specified AWS account. If the role does not belong to the AWS account, you must delete the log streaming destination in the admin console and create a new one.
Delete a network log streaming destination
- Open the Network flow logs page of the admin console.
- For the integration that you want to delete, select the Action dropdown, then select Delete.
- In the confirmation dialog, select Delete.
Private endpoints
Log streaming can publish logs to a host that is directly reachable over the public internet, in which case the endpoint must use HTTPS for security. Alternatively, log streaming can publish logs to a private host that is not directly reachable over the public internet by using Tailscale for connectivity. Plain HTTP may be used since the underlying transport is secured by Tailscale using WireGuard.
Use of log streaming to a private host is detected automatically based on the host specified in the endpoint URL.
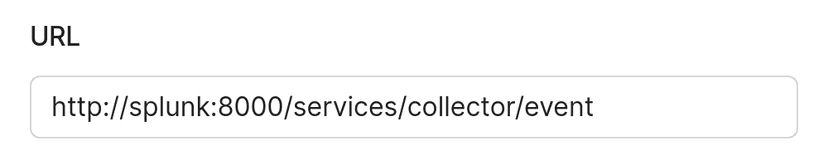
The host must reference a node within your tailnet and can be any of the following:
- The name of a Tailscale node (for example,
splunk). - The fully-qualified domain name of a Tailscale node (for example,
splunk.yak-bebop.ts.net). - The IPv6 address of a Tailscale node (for example,
fd7a:115c:a1e0:ab12:0123:4567:89ab:cdef).
Only IPv6 addresses are supported for log streaming. IPv4 addresses are not supported for log streaming because Tailscale uses CGNAT for IPv4 addresses assigned to nodes within a single tailnet. This can present an issue because IPv4 addresses can be reused across a tailnet. IPv6 addresses are not reused, and hostnames will always route to the correct node.
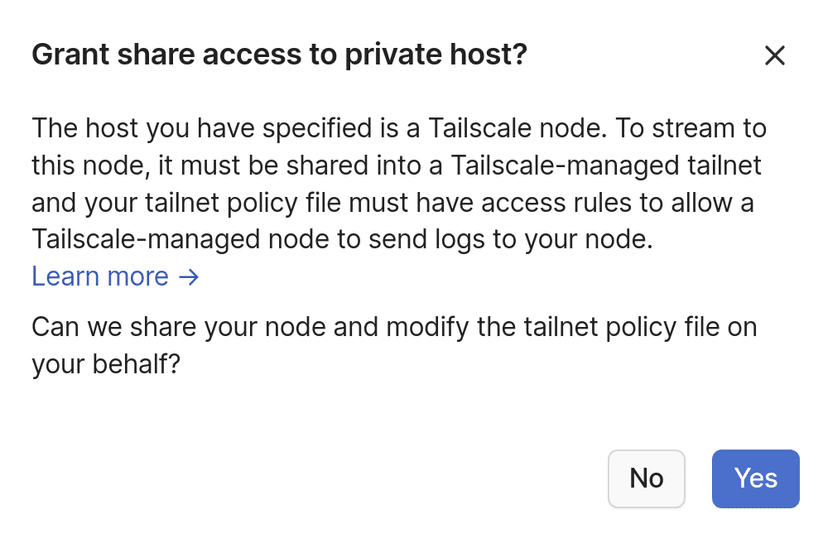
Log streaming to a private endpoint operates by sharing your node
into a Tailscale-managed tailnet, where a Tailscale-managed node will
publish logs directly to your node. This requires both sharing your node
out to Tailscale's logstream tailnet, and modifying your tailnet policy file to support incoming traffic to your node from the logstream@tailscale user.
When adding or updating an endpoint that points to a private host, the control plane may need to share your node and/or update the tailnet policy file on your behalf. If additional configuration changes are needed, a follow-up dialog box will ask you for permission to perform the necessary actions. Audit log events will be generated for these operations and the actions will be attributed to you.
After adding or updating the endpoint, the node will be listed on the
Machines page of the admin console
as having been shared out to the logstream@tailscale user.
Also, the tailnet policy file will be modified with a rule similar to the following:
{
// Private log streaming enables audit and network logs to be directly
// uploaded to a node in your tailnet without exposing it to the public internet.
// This access rule provides access for a Tailscale-managed node to upload logs
// directly to the specified node.
// See https://tailscale.com/kb/1255/log-streaming#private-endpoints
"action": "accept",
"src": ["logstream@tailscale"],
"dst": ["[nodeAddressV6]:port"],
}
You can use the visual policy editor to manage your tailnet policy file. Refer to the visual editor reference for guidance on using the visual editor.
where:
nodeAddressV6is the IPv6 address of the Tailscale node.portis the service port for the log streaming system.
The IPv6 address is specified as the log stream publisher that can communicate with your node over v6 of the Internet Protocol.
Only IPv6 addresses are supported for log streaming. IPv4 addresses are not supported for log streaming because Tailscale uses CGNAT for IPv4 addresses assigned to nodes within a single tailnet. This can present an issue because IPv4 addresses can be reused across a tailnet. IPv6 addresses are not reused, and hostnames will always route to the correct node.
Since log streaming to a private host may require the ability to share nodes and the ability to update the tailnet policy file, only the Admin and Network admin roles have sufficient permissions to unilaterally make use of private endpoints. The IT admin has the ability to share nodes, but lacks the ability to update the tailnet policy file. An IT admin can still make use of private endpoints, but requires either an Admin or Network admin to manually update the tailnet policy file before logs can start streaming.
If your tailnet is configured to use GitOps for management of Tailscale, you will receive
an error when Tailscale attempts to update your tailnet policy file to support incoming
traffic from the logstream@tailscale user. To avoid this error, first use GitOps to add an
access rule that lets incoming traffic from the logstream@tailscale user reach the node that you use for the private endpoint, and then add your private endpoint as the log
streaming URL.
Additional SIEM systems
We strive to support many common SIEM systems used by our customers, but we cannot support all the commercial and open-source SIEM and logging tools available. Some SIEM systems have Splunk HTTP Event Collector (Splunk HEC) compatible endpoints such as DataSet by SentinelOne. If your SIEM supports Splunk HEC, configure configuration audit log streaming and network flow log streaming per the instructions above to stream logs directly to your SIEM as if it were Splunk.
If we do not support your SIEM system, you can use Vector, an open-source high-performance observability data pipeline, to ingest log data from Tailscale by using Vector's Splunk HEC support and deliver it to Vector's many supported SIEM systems, called "sinks" in Vector's terminology. Vector supports a number of sinks such as object storage systems, messaging queuing systems, Grafana Loki, New Relic, and more.
Vector deployment
To use Vector with log streaming from Tailscale:
- Follow Vector's deployment guide to deploy a machine running Vector to your infrastructure.
- Configure Vector's Splunk HTTP Event Collector (HEC) source to allow Tailscale to send log data to Vector.
- Configure the Vector sink for your SIEM as the destination for the log streaming data.
- Configure configuration audit log streaming and network flow log streaming per the instructions above to stream logs to your Vector instance, ideally using private endpoints.
Vector example configuration
The Vector configuration below receives data from the splunk_hec source and outputs data to the file sink:
# /etc/vector/vector.yaml
sources:
splunk_hec:
type: "splunk_hec"
address: "100.x.y.z:8088" # Your Vector Tailscale device's IP or hostname
valid_tokens:
- "YOUR TOKEN"
sinks:
file_sink:
type: "file"
inputs:
- "splunk_hec"
path: "/vector-data-dir/tailscale-%Y-%m-%d.log"
encoding:
codec: "json"