

Most of us have heard of role-based access control (RBAC) and its slightly updated successor, attribute-based access control (ABAC). But we don’t always appreciate all the great ideas they contain.
The most common “RBAC” systems today have been stripped down in ways that make them considerably weaker than the original concept. By going back to the original, we can build a true RBAC/ABAC security model that’s both simpler and more powerful than what you’ve likely seen before, for both very small and very large networks.
People often tell us how surprised they were that their security policy required so few rules to express. That’s not an accident!
But first, some history.
From DAC to MAC
RBAC and ABAC concepts and terminology originated in the U.S. military, decades ago. Role-Based Access Controls (Ferraiolo and Kuhn, 1992) is a pretty good introduction.
I’ve never been in the military and I didn’t know anything about access control back in 1992, but here’s what seems to have evolved.
First there was Discretionary Access Control (DAC), which is still common today. With DAC, the owner of an object can grant permissions on it.
So if you own a file in Unix, you can set
the file permissions (“modes,” hence chmod for “change mode”) to
grant other people read or write or execute access to it. Or if you own a
Google Doc, you can press the share button and grant access, and so on.
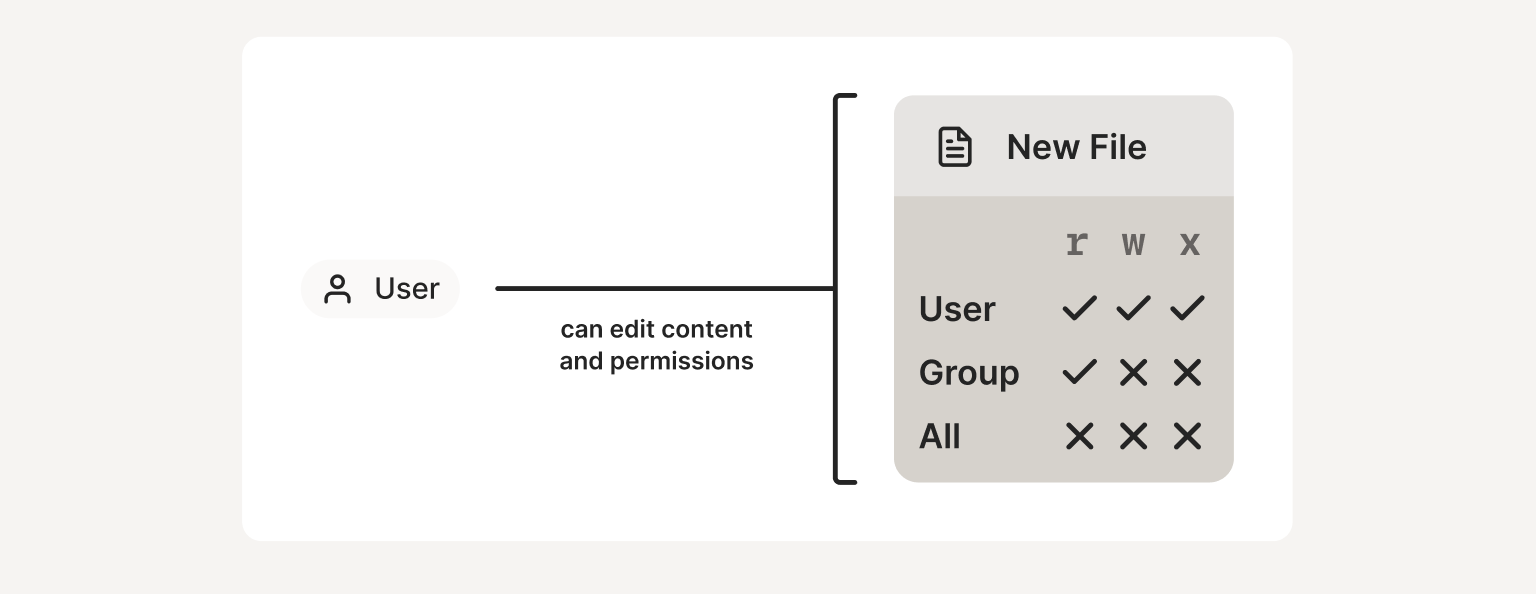
DAC: By granting read, write, and execute permissions to individuals and groups, users have complete control over both the content and the permissions of the objects that they create.
Military people don’t much like DAC, because it’s a little too easy for super-secret stuff to get reshared in non-policy-compliant ways. But it’s still common and pretty reasonable among regular people.
Mandatory access control (MAC) tightens that up. MAC is considerably harder to explain, since you don’t see it as often. When you do, you may not think of it as “access control.”
[Note: don’t confuse MAC (mandatory access control) with “MAC address” (media access controller address) used in networking. They’re unrelated.]
MAC is when some administrator or administrative rule somewhere defines the rules. With MAC, your ability to do something doesn’t let you share that ability with others.
Wikipedia gives one good example: TCP and UDP port numbers. If you bind to one local port (presumably without SO_REUSEADDR), nobody else on that machine can use that same port, no matter how privileged they are. The non-overlapping requirement for ports is “mandatory.”
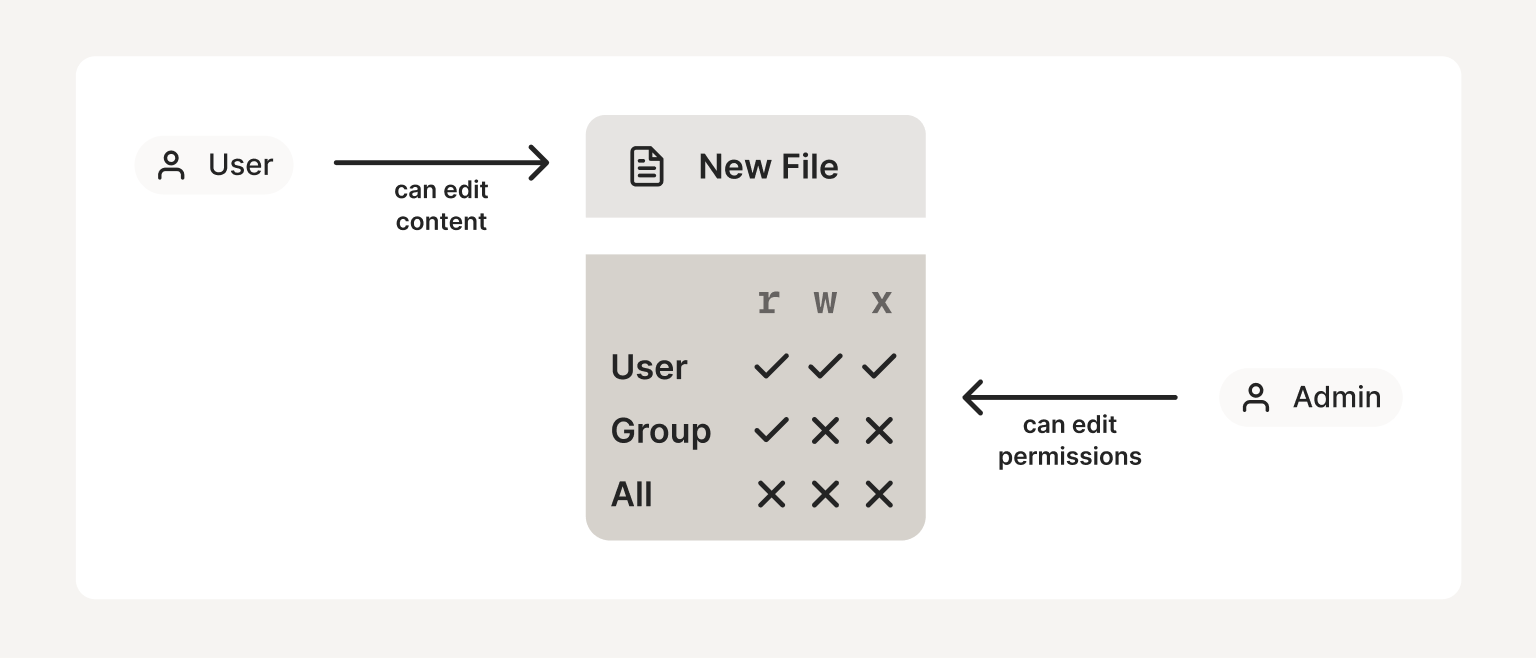
MAC: Users assign a type to an object, which then inherits associated permissions set by an admin or policy. Users cannot edit or assign permissions, even if they have been granted to them.
In my earlier article about file locking, I talked about the difference between advisory locks and mandatory locks. If you hold an advisory lock, you can tell other apps it’s safe to read the file; if you hold a mandatory lock, the rules say they’ll be prevented from reading, no matter what.
When controlling access to documents or systems, you can see why the military was excited about MAC… in theory. The dream is to be able to make a doc “for your eyes only” and prevent any other eyes from reading it, even if your eyes would like to share. Imagine a locked room with a security guard out front, and you can only get into the room if you show your badge, and the guard stops you from bringing in a camera. You have access to the docs in the room, but you can’t share them.
That example should give us a clue that MAC in digital systems is easier in theory than in practice. A full-on MAC system is very hard to actually enforce. Digital restrictions management (DRM) is a type of MAC, where the recipient of the file supposedly does not have the ability to share it further, and every BitTorrent user knows how well that works in real life.
Two-factor login as MAC
Although you might not have thought of it this way, another type of mandatory access control is multi-factor authentication (MFA or 2FA):
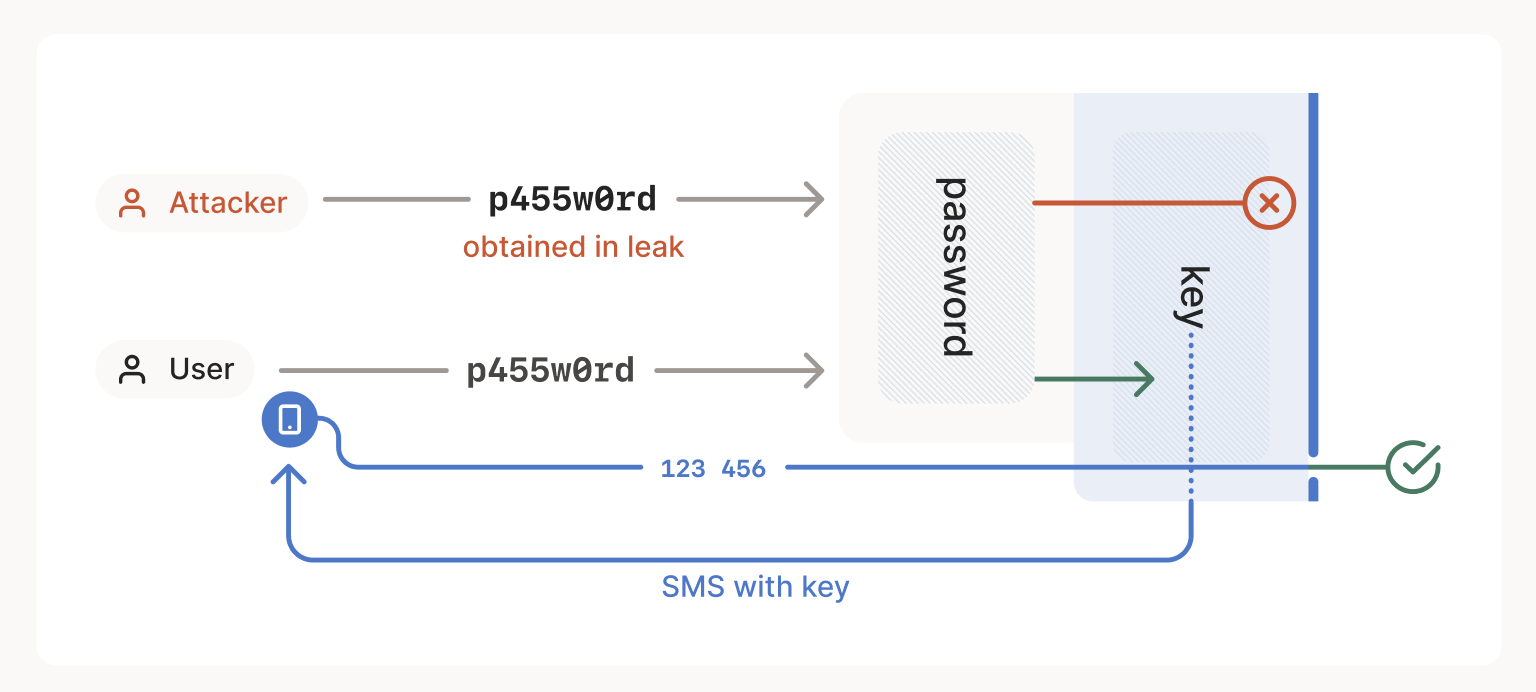
2FA as MAC: Passwords can be shared, but hardware security tokens cannot. Passwords are DAC, while security tokens are MAC.
You can use MFA to restrict login to a computer or a service so that only a particular person can do it. And if that person isn’t an admin on the computer, they (supposedly, if the computer is perfectly locked down) won’t be able to share that computer further, not even by sharing their password. Login is mandatory, and sharing the second factor is (supposed to be) impossible.
Photo sharing as DAC or MAC
For another example, take photo sharing. On some services (poorly-implemented ones in particular), anyone with the right “secret” URL can access a given photo or message or file. Of course, anyone with that URL can re-share it: that makes it DAC.
On other services, you can’t access a document unless you have the URL and you’re logged in with an account that has rights granted to see the file: that’s MAC. Even if someone can access the file using a particular URL, resharing the URL isn’t enough to reshare the file.
(Of course, if a person can download the file and just send you a copy, then… so much for that. This is why some people consider the security of “secret” URLs to be mathematically equivalent to MAC, since sharing a URL is about as hard as sharing a file nowadays. One difference, though, is that you can un-share a URL by locking it down, but you can’t un-share a file that has already been sent.)
MAC is too much
Very traditionally, MAC in the military was built around “multi-level security,” the idea that rather than just admin and non-admin users, there could be various levels of access. They originally conceived of this like concentric circles (“top secret clearance” vs “secret clearance” and so on), but that turned out to be too unexpressive.
Nowadays access controls are usually more like separate flags or subgroups. SELinux, for example, gives you fine-grained control over every permission in every process, compared to old style “root” vs regular user rights. This turns out to be nightmarishly complicated to actually use, unless you’re the NSA (who wrote SELinux). And maybe even if you are.
The MAC concept, in general, turns out to be both too restrictive and too vague. It’s hard to know precisely what people are referring to when they talk about mandatory access control, other than the one constant: it is predictably annoying to use.
Getting more concrete: RBAC and ABAC
RBAC is a subset of MAC. It’s a particular type of MAC, but it’s more concrete, so it’s easier to talk about and work with.
It starts out like the “users and groups” model you’ll have seen in many places. With RBAC, some admin puts users into groups, and someone else can share a resource (file, computer, etc) with a group (role), and the system enforces which of those roles can access the resource. The recipient of the share doesn’t necessarily have the right to reshare, at least not without making a new copy.
Attribute-based access control (Hu, Kuhn, and Ferraiolo, 2015) is a further refinement of RBAC that adds a few more details. “Attributes” can include things like the location, client device platform, authentication type, or http cookies of a given user. When the system is deciding whether to grant a user access to a resource, an ABAC system checks not just their RBAC role (group), but also various other attributes the person might have.
If you’ve ever been offered a reCAPTCHA when logging into a service while your friend next to you has not, you’ve encountered ABAC.
ABAC is useful, and you almost always want to use a few of these extra attributes, especially in Internet-connected systems with lots of attack vectors. But conceptually ABAC is like a slightly more convoluted RBAC, and the attribute parts are mostly implemented centrally in your identity provider, so let’s leave it alone and stick to RBAC for our discussion.
You probably haven’t tried real RBAC
We mentioned that RBAC is “like” the users and groups model you’ve seen before. But let’s get specific. Look at a simple filesystem security model, say on Windows.
(I would use Unix as an example, but classic Unix file security is rather unusual and defies categorization. It gives you only a single owner, a single group, and self/group/other file modes. Nowadays Linux also supports facls, which are RBAC, but nobody knows how to use facls, so they don’t count.)
On Windows, each file (or directory) has a list of users and groups and what each of them is allowed to do to that file. This is an access control list (ACL).
The owner sets the ACL, and then the operating system enforces it. That’s MAC, right?
Yes, mostly. It turns out any person reading the file can just make a copy and set the permissions of that copy, which is sort of DAC, or just really poorly enforced MAC. But enforcing MAC on actual files is hard. Let’s leave that to the military and focus on the intended ACL semantics for now.
In a Windows filesystem ACL, you have:
- User: a person who acts on a file. The user is called the “subject” in ancient RBAC terminology.
- Group or Role: an administratively defined collection of users.
- File: a resource being controlled. (Also called the “object,” like in grammar. A subject acts on an object.)
- Permission or Entitlement: a subject-action-object rule. Sometimes we consider a subject to “have” an entitlement or an object to “allow” a permission, but it’s the same thing, from two different points of view.
- ACL: a list of entitlements.
Each file has one ACL (a list of permissions). The ACL might inherit some entries from the ACL of the subdirectory it’s in, or not, but that’s not important right now.
Files with identical ACLs might have their ACLs deduplicated on disk, but that’s an implementation detail.
Importantly, every file has one ACL. If you want to change who can access the file, you have to either:
- change membership for one of the groups (roles) in the ACL; or
- change the ACL to add or remove permissions.
If you want to change the ACL for a bunch of files at once, you can change group/role memberships (easy), or find all the relevant files and change the ACL for each (slow and error prone).
All is well and good until you have hundreds of files to change ACLs for.
That last bit is where things start going wrong. Almost every system you’ve ever used, RBAC or not, makes you find all the interesting objects and change their ACLs. And you probably have not kept careful track of all those objects. In a distributed system, those objects could be all over the world, stored in many different kinds of storage systems, all relying on your identity system, and if you realize a given permission was wrong, you have to hunt down every single copy of that permission and fix each one, or else you have a security problem. Oops.
Second attempt: one group per ACL
After you’ve been bitten by that enough times, you’ll try something new: moving as much information as you can out of the ACLs (which are scattered everywhere), and as much as you can into user groups (which are centrally stored and can be audited).
Again using the Windows filesystem as an example, perhaps you create
groups report-readers and report-writers. All your reports will be
readable by report-readers and writable by report-writers.
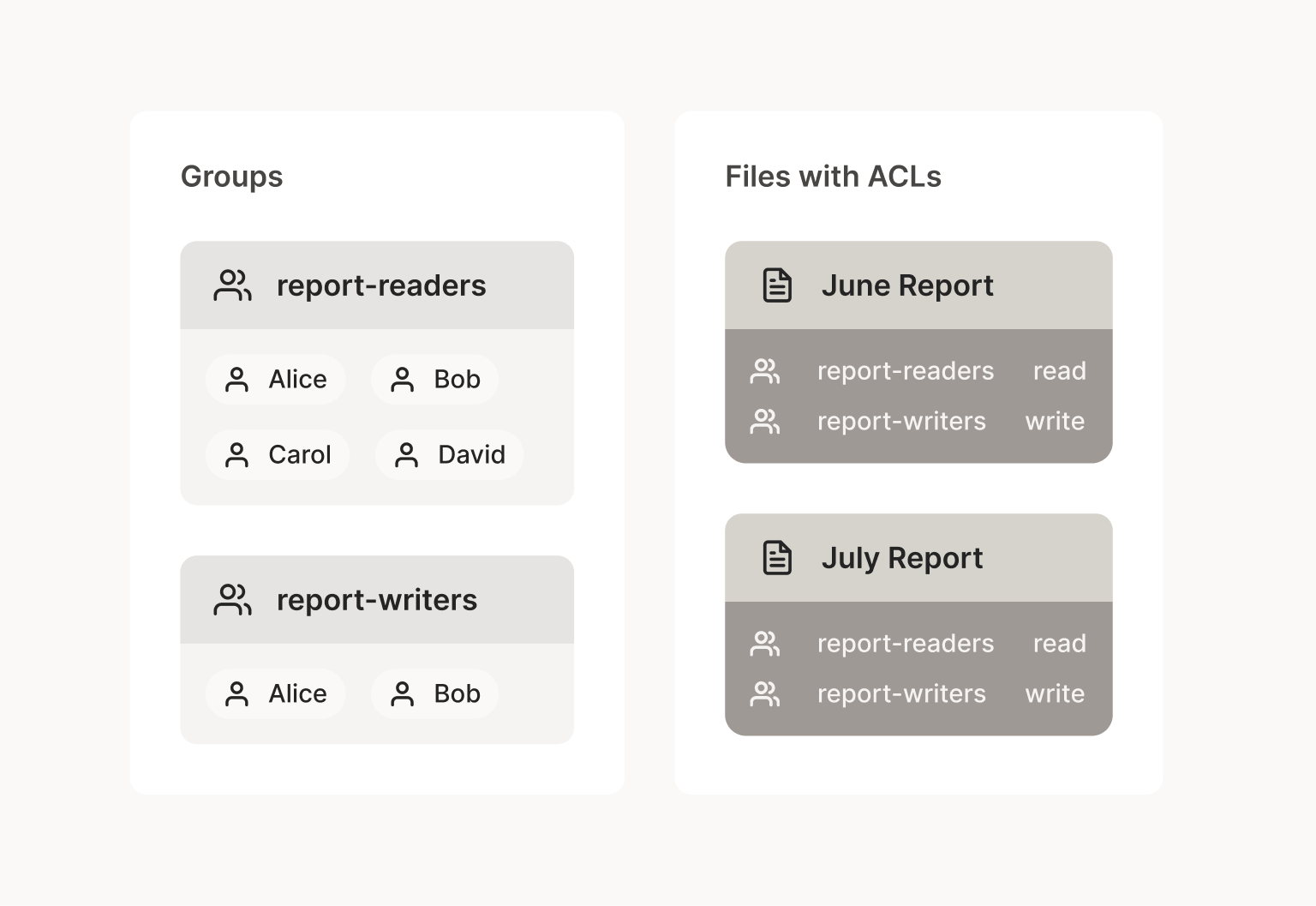
A less experienced person than yourself might have just made a group
report and given it both read and write access, but this is not your
first rodeo, so you don’t fall for that mistake this time. It very
often turns out that the readers of a file should be a wider group
than the writers. Occasionally (e.g. in audit logs) the writers should
even be a disjoint group from the readers.
This per-file-type group structure is an example of the Don’t Repeat Yourself (DRY) principle in action: the problem is the ACL was repeated in every single file, so we take out the repeated part and put it in one place.
This is an improvement, especially in larger organizations with a lot of objects. It works pretty well, but there are some major problems with this method too:
- You now need some kind of IAM admin access if you need to change the
membership of
report-readersandreport-writers. Before, you could change file access without any special rights. This creates pressure to give too many people IAM access, which is risky, or to lock down IAM access, which is too restrictive. - End users can still wander around and edit the ACLs on individual reports whenever they find an exception (“but Alice really really needs to read file xyz!”), breaking your wonderful system, without you knowing it.
- Now you need to create a different set of groups for every ACL combination. Before you know it, every engineer in the company is a member of 975 different groups, two per file type they have access to. And you have to review each group’s membership separately. This is more auditable than the old ad-hoc file permissions, but not by much.
The missing concept: object tags
At this point, we’re going to have to leave filesystem ACLs behind, because of some very bad news: the above is how filesystems have already been designed. You’re stuck with it. You are probably not going to solve any of the above problems in your legacy filesystem and OS. Sorry.
The better news is that everything happens in stateless containers nowadays, and most VMs have passwordless sudo, so filesystem security has become largely irrelevant. Instead, web apps and NoSQLs enforce any kind of permissions they want via their API. It’s probably not a coincidence that this has happened, since the need for fine-grained distributed security keeps increasing, while filesystems remain trapped in the 1980s.
Anyway, let’s design the kind of permissions we want! Everyone else does.
First, note that the above filesystem ACL scheme is not really RBAC in
the original sense. User groups are supposed to be “roles,” but if you
have 975 groups like report-readers and report-writers, those
aren’t really human-relevant roles. The HR department doesn’t know if
your new employee should be a report-reader or not. That decision is
too low-level.
Our first clue that things have gone wrong: those “user groups” are named after file types, not user types.

The group-per-file-type format is too flat: it has lost the semantic
meaning of why each person is in each list. If Bob changes jobs,
we’ll have to edit the membership of possibly many different groups.
This is better than tracking down every file of type report to
double check whether it still has the right permissions, but it’s
still too error prone.
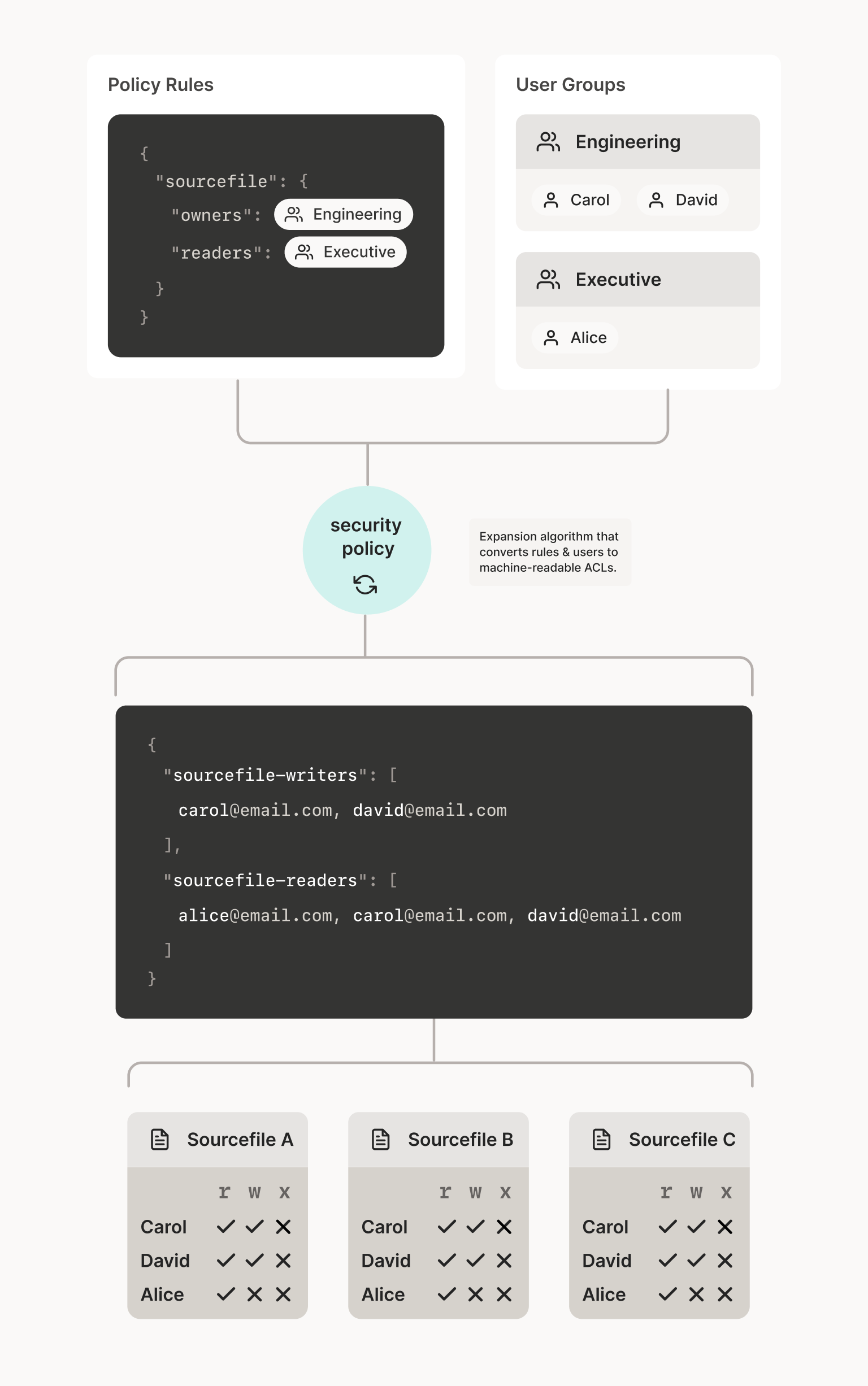
Let’s instead say you have these roles: Accounting, DevOps, Engineering, and Executive.

Then we can define the ACLs as a set of policy rules:

It says the same thing as our original flat model, but suddenly it says what we’re really trying to express, by adding exactly one level of indirection. We can talk about human-relevant roles, as defined by the HR department, and tags, as defined by the security team, and how they should be tied together.
Since we’re inventing a new permission system anyway, let’s clean that up even more:
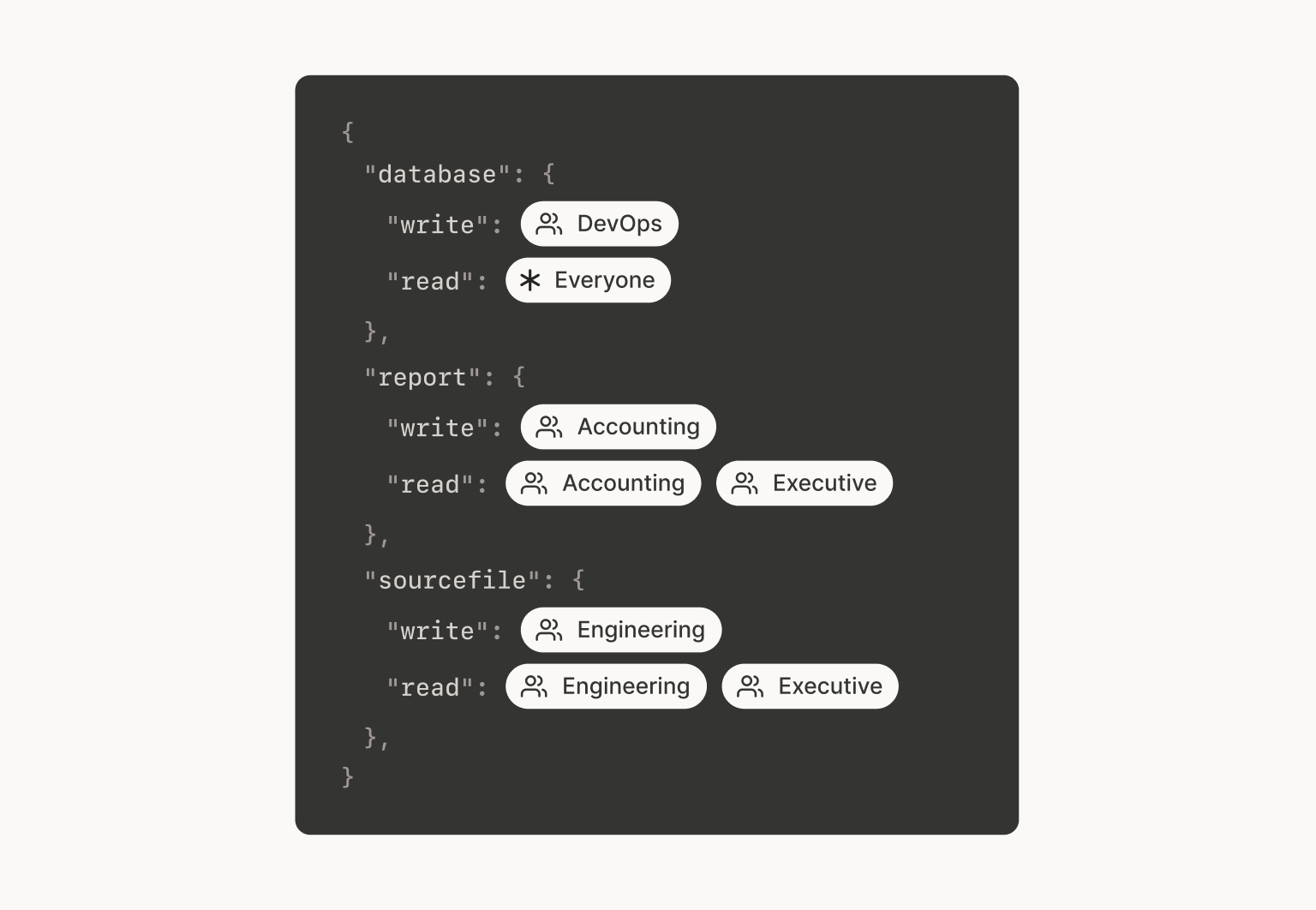
Later, when we’re trying for SOC2 compliance, we can change the
readers for database to, say, [DevOps, Prod], and it’ll lock down
every database-related object at once.
Finally, let’s add two more features:
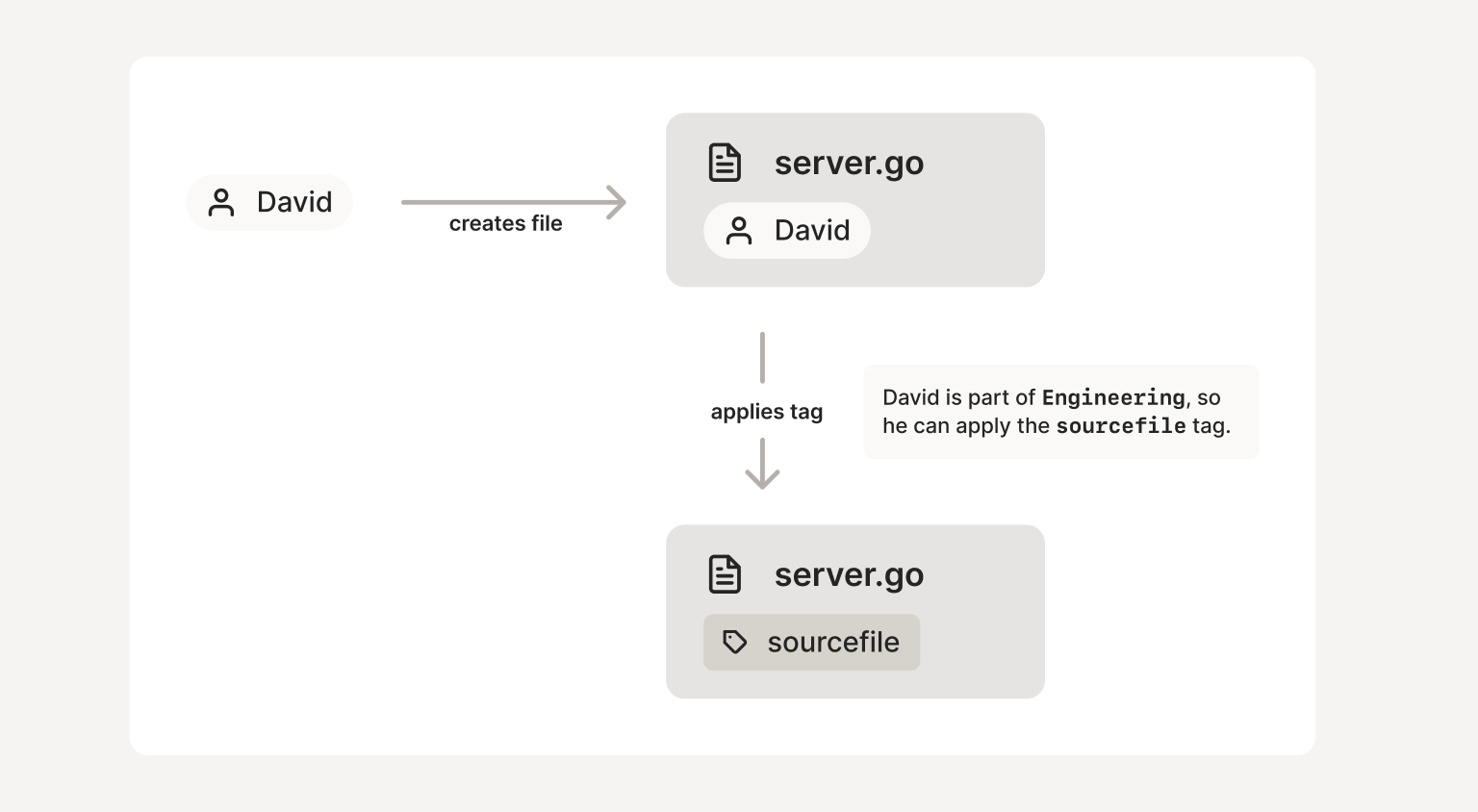
Instead of a single type, an object can have zero or more tags. So a
source file that relates to the database might be tagged as both
database and sourcefile, and get the union of the two permission
sets.

Secondly, only an “owner” of a given tag is allowed to apply that tag to any
object. Below, nobody outside Engineering is allowed to
tag something as sourcefile. This prevents accidentally sharing
objects between users who should be completely isolated, or
incorrectly applying existing policies in situations where they
weren’t intended.
That’s where the Mandatory Access Control comes back in, but now it doesn’t require global admin access to the security policy for every edit. Each tag owner can grant access to their objects, but which access they can grant is controlled by the overall security policy.
In a network system like Tailscale, we don’t really talk about readers and writers, like you would with files. Instead, we want to define nodes and ports and who is allowed to connect to which. So we might define rules like this:

Then, everyone in Engineering can launch a dev-api-server node
that’s allowed to accept unencrypted connections (TLS is hard!) from
any dev-api-client node, but not vice versa. And only people in Ops
can launch prod-api-server and prod-api-client nodes, which we’ll
assume will be properly configured to handle https, and reject
unencrypted http.
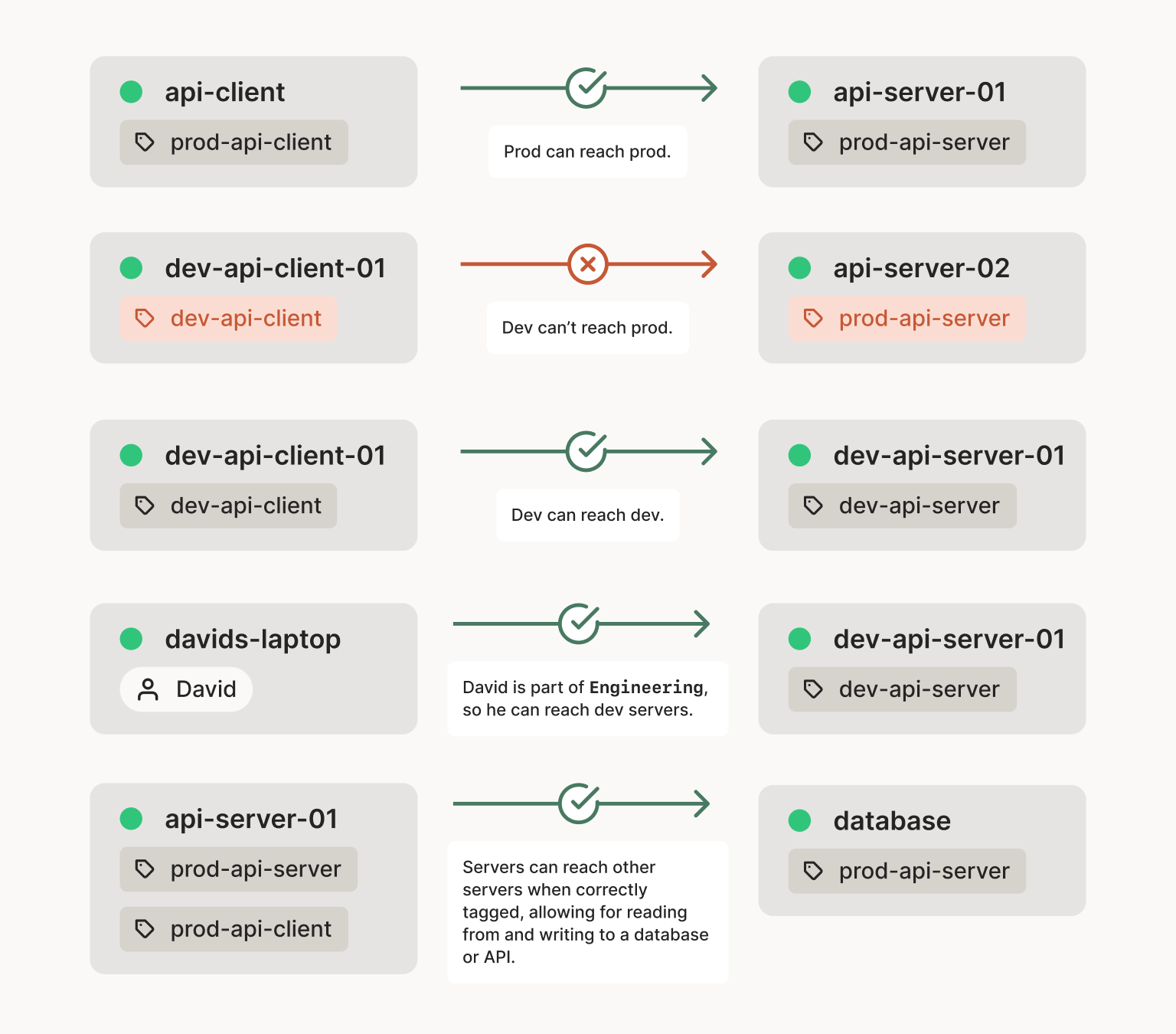
Notice that here, we’ve recursively used some tag names to define
permissions for other tags. Someone in Ops can launch a node and tag
it prod-api-server. It will then get the permissions and entitlements
associated with prod-api-server instead of Ops. (This is important so
that prod-api-server instances can’t just launch more instances, like
Ops can.)
(Real Tailscale ACLs and tags are like this, but more detailed.)
Separation of responsibilities
If we were to try and retrofit this back into legacy-style filesystem permissions, we could observe that roles and tag definitions are really the same kind of object (lists of users), with an expansion algorithm (“security policy”) between them:
You could write a set of scripts that auto-generate your /etc/group
content like this, based on a set of role definitions and programmatic
group membership rules. I know some enterprises do that. It’s
nonstandard and a pain to maintain, and it tends to be batch-updated
from a cron job, which means when you change the definition for a
tag or the membership list for a role, you have to wait for the next
sync cycle before any of it takes effect. But yes, it can work, and
it’s a lot better than typical operating system defaults.
The technicality that “tags” (for ACL purposes) and roles (for user management purposes) are both “lists of users” is kind of misleading; you use them for different things. Most importantly, different people are responsible for different parts of the system:
- Roles describe humans in the identity system (authentication). They change rarely, and are typically set by your HR department at hiring, promotion, or job transfer time.
- Object types (tags) are set by the object owners at creation time.
- Entitlements permitted by (Role, Tag) pairs are defined by a little program (a security policy), set by your security team.
In this architecture, these three types of people need to communicate only rarely.
The writer of a financial report in Accounting doesn’t care who is an Executive, or
whether Executives are allowed to read or write reports. They just
need to know to tag their file as financial-report.
The security team doesn’t care which files are financial-report
(within reason), and doesn’t care who is an Executive. They do need to
write, enforce, and review a policy that financial-report should be
readable only by Executives and Accounting, and taggable only by
Accounting.
The HR team doesn’t know or care about files or security policies. They just care that they hired someone in the Accounting role this week.
Back to network permissions: correctly designing around these concepts can save a lot of friction in a large organization.
When an engineer wants to start a new dev cluster somewhere, why do they need to file a ticket with the security team to open firewall ports? Because the security team is enforcing an informally-written security policy:
- Engineers are allowed to run dev API servers that will accept incoming connections from engineers’ workstations
- …or from dev API clients
- …but are not allowed to initiate outgoing connections. Usually.
- Oh, also, Carol’s dev API server is allowed to initiate connections to the database server.
It would be better if the security team could just write down the security policy as a chunk of code instead, and have it enforced globally across the network.
What now?
All this is not supposed to be anything new. Users, roles, object types, and policies are all things from the 1992 paper that introduced RBAC to the world, albeit with different terminology.
Almost everyone already uses users, groups, and ACLs. Many people assume they’re done and call that RBAC, but it isn’t. Almost nothing implements the full RBAC model:
- Every person is a User (subject).
- Every user has one or more Roles.
- Every object has one or more Tags.
- A “security policy” defines a formula to translate from (Role, Tag) into Entitlements.
- An enforcement layer compiles the security policy and generates the effective list of entitlements (ACL) for each object.
Oddly, this model is not really harder to build than the common users+groups model… as long as we do it in the core of a system, from the start.
As we said at the top, this is the rationale behind Tailscale’s unusual take on RBAC, ABAC, and security policies. Tailscale objects are devices and ports rather than files, but all the concepts apply the same way as they do in a filesystem.
The result is a deceptively clean design in which a device or container owner can apply a tag; the security team can decide who owns which tags and which permissions that tag grants to which roles; and the identity/HR team can decide which users are in which roles.
 Avery Pennarun
Avery Pennarun




