Tailscale can help you securely connect to anything on the internet, including remote resources in Kubernetes clusters. And we can establish connections even when the path is not ideal — but that may involve trade-offs that aren't right for your application. In this post, solutions engineer Lee Briggs outlines how to minimize latency with direct connections in Kubernetes environments.
Kubernetes, direct connections, and you

Kubernetes deployments have a way of surfacing networking irregularities that might have gone unnoticed on a smaller scale. When we talk to teams using Tailscale in their Kubernetes clusters, one such problem we sometimes encounter is that certain configurations make direct connections between nodes difficult or impossible to create. As a result, traffic is relayed through shared infrastructure, leading to bandwidth bottlenecks and latency issues.
As we've worked with more and more of our users deploying Tailscale-connected clusters — using our operator or their own manifests — we've learned some tricks about how Kubernetes networking works in practice and how it interacts with the Tailscale approach. In this post, I outline some of the background complexity involved in networking with Kubernetes, present some emerging best practices that can help ensure you can create direct connections, and discuss some of what doesn't work. If that really piques your interest, at the very end I will foreshadow some hackier approaches.
DERP
First, some quick background on why there are different “direct” and “relayed” connections at all. Tailscale can create connections in a wide variety of networks through a combination of NAT traversal and our DERP servers: shared, globally distributed infrastructure that Tailscale operates and that relay messages about client connectivity. DERP servers are also leveraged when two clients can’t negotiate a direct connection to each other. When first negotiating that connection, or when a relayed connection is necessary, the Tailscale client will use the DERP server with the lowest round trip latency.
Users whose connections are being relayed by Tailscale’s DERP servers often don’t even notice; the extra hop it introduces between two clients is often only a few milliseconds different. And even though we apply some traffic shaping to ensure availability of a shared resource for everybody, the vast majority of tailnets stay within the boundaries of acceptable usage and don’t bump up against the soft bandwidth or throughput limits.
However, once the usage of Tailscale starts to ramp up within an organization, bandwidth and latency can start to be noticeable to users. On the Tailscale solutions engineering team, we often engage customers at this stage to ensure we architect their Tailscale set-up to ensure direct connections between their devices. In September, I hosted a webinar where I talked extensively about the different types of connections, how to identify them and some tips and tricks on how to ensure you get public connections.
Most of the webinar focused on direct connectivity at the virtual machine or cloud provider compute level, but customers consistently ask — how can I get the same direct connections in Kubernetes?
The Kubernetes of it all
Every Kubernetes cluster has a CNI (container network interface) which has the responsibility of handing out IP addresses to pods in the cluster. There are a lot of different CNI implementations, and they solve this problem of handing out IPs to pods in a variety of different ways, but they all have to figure out the same problem. A core tenet of Kubernetes is that in order for the cluster to function correctly, every pod should have direct connectivity to all the other pods in the cluster. Most of the time, this means guaranteeing layer 3 connectivity to each other (there are caveats, such as Calico in VXLAN mode), so the CNI generally hands out a bunch of addresses to pods from a specific CIDR block; what can be different is the way the CNI decides what that CIDR block is.
How this relates to Tailscale is fairly simple: Tailscale just becomes another pod. It gets an IP address, and can connect to any other pod in the cluster just great. You can see this visualized in the diagram below.
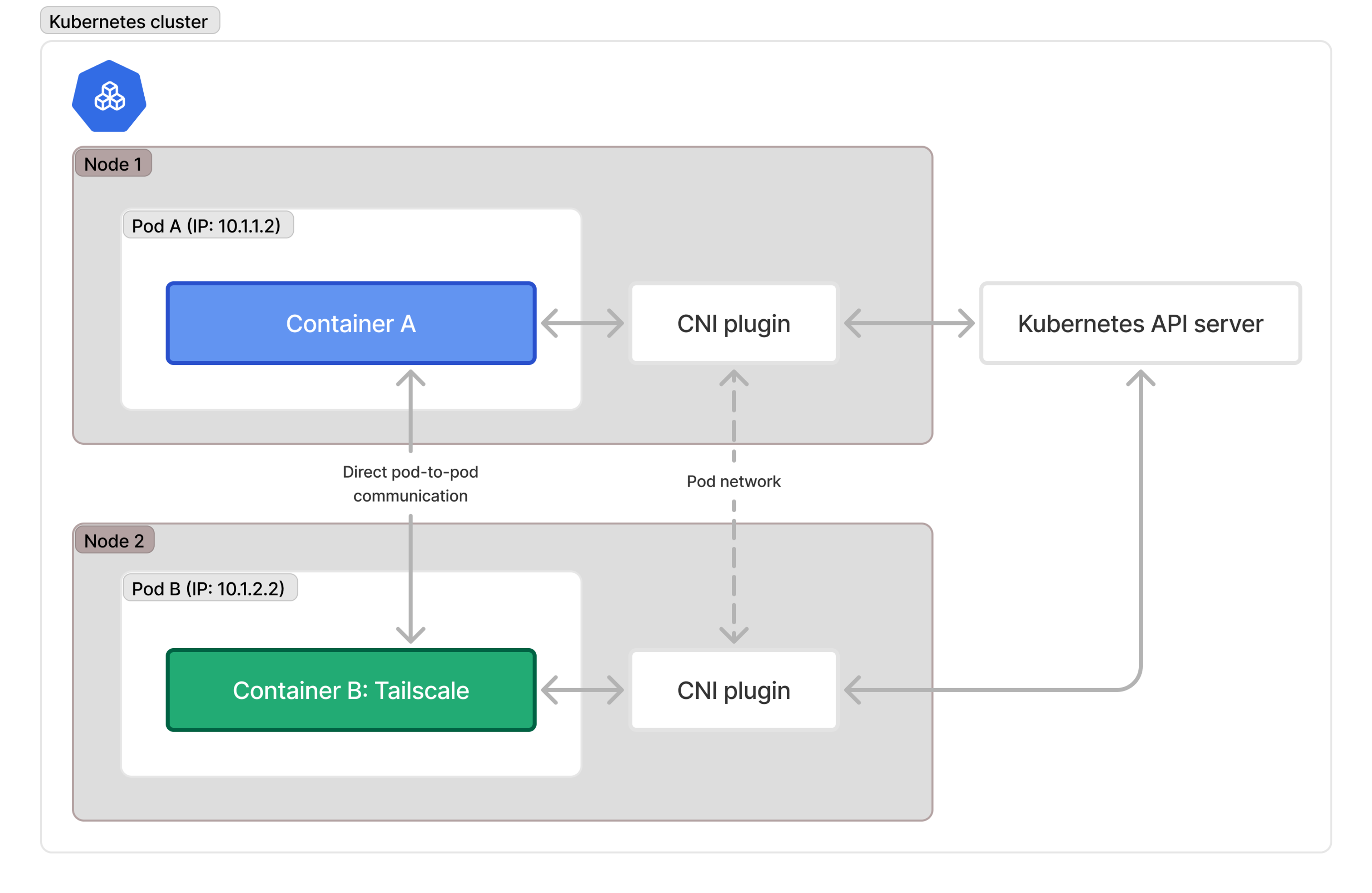
This is all well and good for communication between pods in the same cluster. And indeed, two Tailscale nodes inside a Kubernetes cluster can virtually always establish direct connections to each other, for example.
But if you’re installing Tailscale into a Kubernetes cluster, you almost certainly want to access the Tailscale pod from some external network. Tailscale, using its NAT traversal, will send information to the DERP servers on the public internet about its public “endpoints” and the port it's using for outbound connectivity, and the path it takes to do that is very important for getting direct connections. The use of a CNI is also not something to be ignored, as it creates an additional consideration to getting direct connections.
The connections are NAT direct
(I make no apologies for the pun.)
The biggest barrier to getting direct connections between Tailscale clients is NAT, specifically a “hard NAT” which does some form of port randomization on outbound connections. This randomization means that when Tailscale sends outbound traffic, the NAT device uses a different port for every outbound connection (you can hear more about this in the webinar, or in the doc) and as a result, Tailscale can’t reuse that port to create direct connections.
Here I am doing some hand-waving. Kubernetes networking is complex, and there are qualifications to most of the sentences in the last two paragraphs. Notably, we’re describing the NAT on one end of a connection, and glossing over the other end, which can have an effect. (In fact, this problem often pops up when Tailscale gets installed in the cluster to expose some cluster workloads to user devices that themselves might be behind hard NAT.) In general terms though, when we hear that a Kubernetes set-up is not making direct Tailscale connections, we start our investigation with the NAT.
What’s really relevant here is that when you use Kubernetes, and introduce a CNI where every pod has its own IP address, all outbound connectivity happens through the hosts’ network interface. Those of you reading this who’ve had to deal with this sort of connectivity before will recognize this as a particular type of NAT, “source NAT” (or SNAT for short).
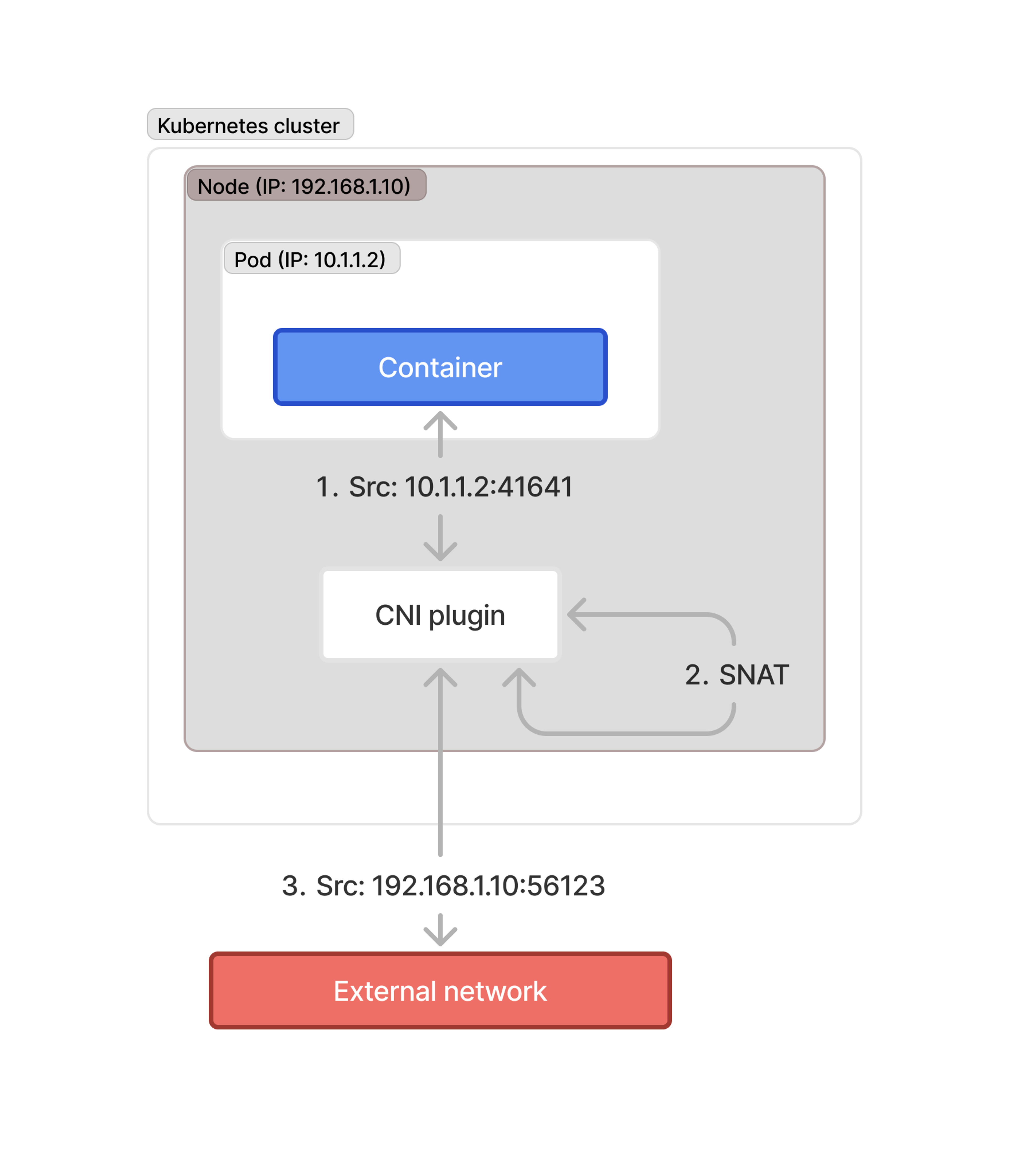
This creates a really difficult situation for Tailscale, because now it's doing all kinds of NAT traversal, out from your network and out from the host itself. You’ll still get connections of course, because Tailscale does its magic to navigate most networks, but direct connections are less likely.
The forecast is “cloudy” for direct connections
(I’m on a roll with these puns, right?)
Now, for those of you familiar with Kubernetes implementations in cloud providers such as AWS and Azure, you’ll be thinking “a-ha! The CNI doesn’t need SNAT, because it hands out an IP directly from the cloud network!” and you’d be right to think that, but don’t get too excited just yet.
While there’s no SNAT required, and the pods are inside the same layer 3 network as the compute hosts, the default setting for AWS CNI for example is to enable SNAT via IPTables and fully randomize port mapping. Azure’s networking has a lot more configurable parts, but it will generally SNAT in its default mode. All these add up to the same thing: more NAT to traverse means less chance of getting direct connections.
What can I do about this?
The Tailscale solutions engineering recommendation to ensure direct connections is to get the side of the connection you have the most control over (in most cases, the infrastructure side) into a “no NAT” situation, whereby the Tailscale device itself has a public IP attached to it. The way to do that in general is:
- Give the node a public IP address
- Open inbound UDP access to the port
tailscaledis listening on
Now for Kubernetes specifically, this will mean 3 things:
- Ensure you have a node with public IPs, obviously
- Set
hostnetwork:trueon the pod spec - Ensure you specify the port Tailscale listens on using the
PORTenvironment variable - Specify a port on the deployment
- Open UDP traffic to the security groups or inbound firewall to allow access to the above port
The steps above will ensure you aren’t navigating a cloud provider’s managed NAT gateway (which will almost always be hard NAT) as well as not getting SNAT’d from the pod to the host. It isn’t particularly appealing, but it’ll work.
I don’t like this, what else can I do?
Sadly, there’s not a whole bunch you can do. Our current stance, at the time of writing, is that we can’t guarantee direct connections on Kubernetes. These limitations are generally design decisions in the Kubernetes ecosystem. This is especially true when leveraging the Kubernetes operator, which cannot easily use host networking for pods it creates.
For now: we’re aware of this issue, and we’re working on it. If your team is interested in using Tailscale and Kubernetes and can’t implement our recommended approach, please get in touch. We’d love to hear from more users about where the actual pain points are, and how they match up with some of our proposed fixes. In the meantime, there are some experimental solutions not quite ready for public consumption, and we’ll outline those in a future blog post.
Share
Author
 Lee Briggs
Lee BriggsLoading...





