Tailscale helps your team build a programmable network layer to connect all of your resources, on your own infrastructure and in the cloud. We also use it ourselves, every day. Tailscale's infrastructure tech lead, Kylie Fisher, explains how that simplifies many of our security concerns.
How Tailscale’s infra team stays small

When I talk to other infrastructure folks at tech conferences, they’re usually shocked to hear that Tailscale’s infra team is just three engineers. Companies of similar size often have multiples of that. How do we manage to get by with so few people?
The honest answer is that we at Tailscale use Tailscale in nearly all of our infra operations. The response to that is sometimes a bit of shock, too. Although not every company is in a position to use their own product as a critical dependency, we have found we can trust and rely on it, which wipes out whole classes of problems from my daily consideration. Issues that used to give me headaches or keep me up at night at previous jobs just don’t come up most of the time — which is nice, because they really aren’t the kinds of issues that I want to spend time and attention on.
I hear similar stories from friends who work at companies that have adopted Tailscale (and the customer-facing teams tell me there are many more). Everybody’s network architecture is a little different, but there’s also a lot of overlap, so I thought it might be interesting to talk about two particular things I don’t think about at work.
I don’t think about networking
This sounds funny for somebody who works at a networking company, I know. But many of the thorny network architecture questions I’ve previously dealt with boil down to ensuring our machines can talk securely to each other. With Tailscale that comes as a default, or can be solved with a simple ACL config change.
At other jobs, I’ve had to weigh tradeoffs of security and complexity when deciding whether to host resources at public or private endpoints. Of course if they’re public, configuration may be simpler, but you have to be super diligent about locking them down as configurations and access needs change. And then there are the risks that emerge as the facts themselves change: maybe it’s not a problem that DNS records expose the names of internal services, until one of the names contains sensitive information, and so everybody involved has to keep track of a threat model all the time.
On the other hand, if they’re private, they’re either in the same VPC — a hassle because providers like AWS require you to recreate a VM to move between VPCs — or you have to configure VPC peering to keep everything connected. Of course this is all possible, and I’ve done it before, but this kind of tedious work is not something I’m excited about, and not something anyone volunteers for.
With our Tailscale configuration, private services can talk to each other in our corporate tailnet across VPCs or even cloud providers, without any special configuration. The result is we can decide which cloud providers to use for services based on things like price and availability, without worrying about how they’ll connect to our existing infrastructure.
One real-world example is our fleet of DERP servers. In case you’re not familiar: Tailscale operates a collection of servers around the world to help clients negotiate direct connections and, in cases where direct connections aren’t possible, relay WireGuard-encrypted traffic. These need to be geographically distributed and have competitive bandwidth pricing, so it really makes sense for us to shop around between cloud providers. From a networking perspective, though, it really doesn’t matter where they live, because they join our tailnet and get simple addresses, and the Tailscale client handles the rest.
You can see how that works in this diagram. Our monitoring service oversees various DERP servers, and it’s completely agnostic to where they are hosted.
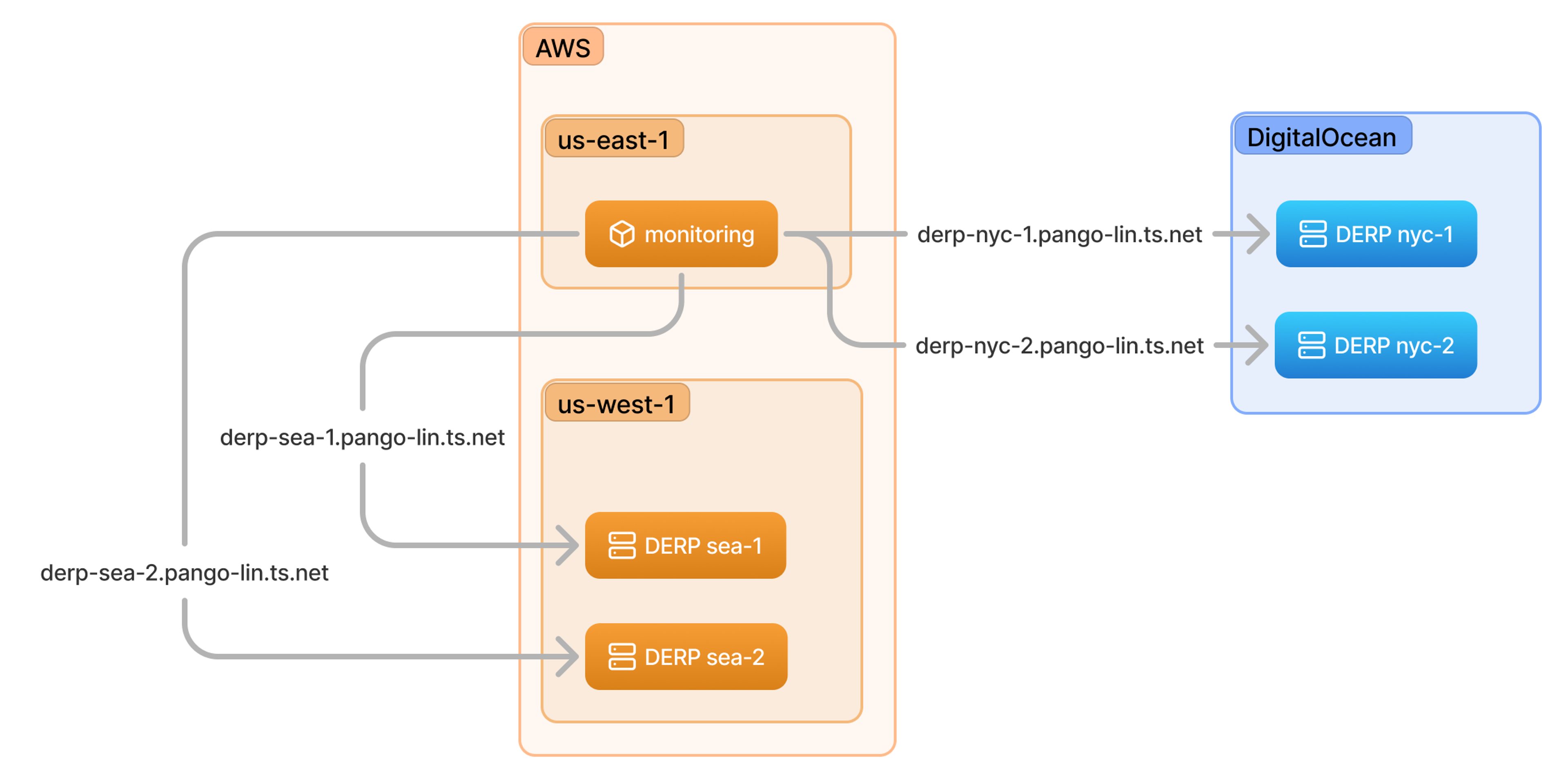
Instead of configuring access controls at the network architecture level, e.g. via security groups and peering rules, we do it through our ACLs.
This ACL block allows machines tagged with monitoring to access port 9100 of any machine tagged with derp, regardless of physical network conditions. That means that adding new DERP servers to our infrastructure and monitoring dashboard entails only a few lines of configuration, even if they’re with a cloud provider that’s fully new to us.
{
"ACLs": [
{
"action": "accept",
"src": ["tag:monitoring"],
"dest": [
"tag:derp:9100"
],
},
}I don’t think about secrets
When I’m not working on infra, I like to immerse myself in the deep lore of the Real Housewives franchise. In so many ways, I have nothing in common with them. But one thing that infrastructure engineers do share with Real Housewives is that we have to deal with a lot of secrets, and it is usually somewhat stressful.
Case in point: we previously used AWS Secrets Manager, which is powerful and handy if you’re contained within the AWS ecosystem. But as you’ll note from the last section, we tend to use whatever clouds are best suited to the application. For example, the fleet of DERP servers I mentioned above are currently hosted with DigitalOcean, Vultr, and NetActuate. Establishing AWS identity outside of AWS is a headache, and often comes with a chicken-and-egg problem of needing to possess a secret to show you are allowed to get a secret.
For most stuff here, we can rely on the fact that every connection over Tailscale is encrypted and authenticated to an identity. So instead of handling access questions at the edges of a given resource, we can manage them at the identity level (usually through group membership) in one place: our Tailscale ACLs.
When we really need secrets, we use setec, a secret manager that we built in-house and that lives as another service in our tailnet. Like any tailnet service, we can use our ACLs to manage access to it. And because it has Tailscale support built into it natively with our tsnet library, we can even drill down access to groups of secrets with Grants, so teams (and even individual services!) only have access to what they need.
So for example, the Grants section of our ACLs has sections that look like this:
{
//...
"grants": [
//...
{
"src": ["group:infra"],
"dst": ["tag:secrets"],
"app": {
"https://tailscale.com/cap/secrets": [
{
"action": ["get", "put", "info", "activate", "delete"],
"secret": ["dev/*", "derp/*"],
},
],
},
},
{
"src": ["tag:derp"],
"dst": ["tag:secrets"],
"app": {
"https://tailscale.com/cap/secrets": [
{
"action": ["get"],
"secret": ["derp/*"],
},
],
},
},
//...
]
//...
}
which allows users in the infra group to read and modify dev/* and derp/* secrets, and machines tagged with derp to access derp/* secrets. All of that is configured in one place, and any changes propagate basically instantly through all devices on the tailnet.
Similarly, I almost never have to think about TLS certificates. For one thing, those same encrypted and authenticated properties mean we get most of the benefits of more complicated approaches like mTLS. Instead of my team and I having to keep track of private keys to generate certs, Tailscale handles the WireGuard key distribution, exchange, and revocation, and, when necessary, the TLS certificates (through Let’s Encrypt).
I still do think about other stuff
Despite all the problems that Tailscale solves for us, we keep very busy here on the infrastructure team. And like everybody else, we would welcome more headcount! But the examples I listed above are some of the most annoying things I have to deal with in the infrastructure world. With those out of the way, I can focus on the more interesting problems of my job.
And if you’re still spending time working on the things I’m not thinking about, maybe your team should try Tailscale.
Share
Author
 Kylie Fisher
Kylie FisherContributor
Parker Higgins
Loading...





