
Not all engineering work at Tailscale requires changing Go internals or deep insights into how to leverage the birthday paradox for NAT traversal. There are countless small bugs and edge cases that we investigate in our quest to meet an unreasonably high percentile of our users’ expectations. This is the story of one such investigation.
In mid-May, Brad deployed a set of stateless reverse proxies in front of Tailscale’s coordination server. That had the expected effect of reducing the number of inbound HTTP connections (measured as open file descriptors) and prepared the way for future optimizations (e.g. handling some simple requests in the proxies themselves). Graphs went down and to the right, as desired 🎉 📉:
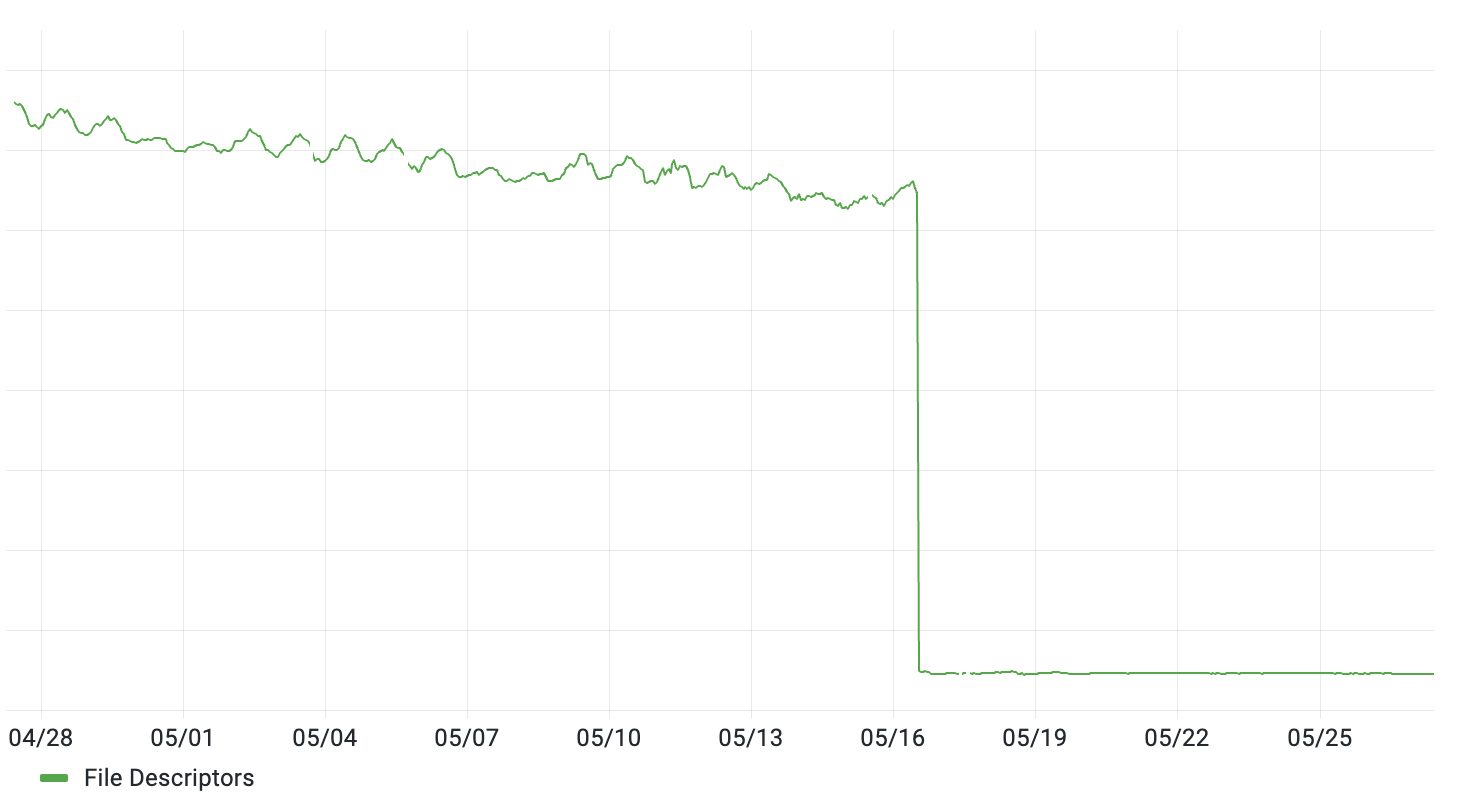
All seemed well, but a couple of months later we noticed that the file descriptor count (while still much lower than before) started to have a noticeable sawtooth pattern:
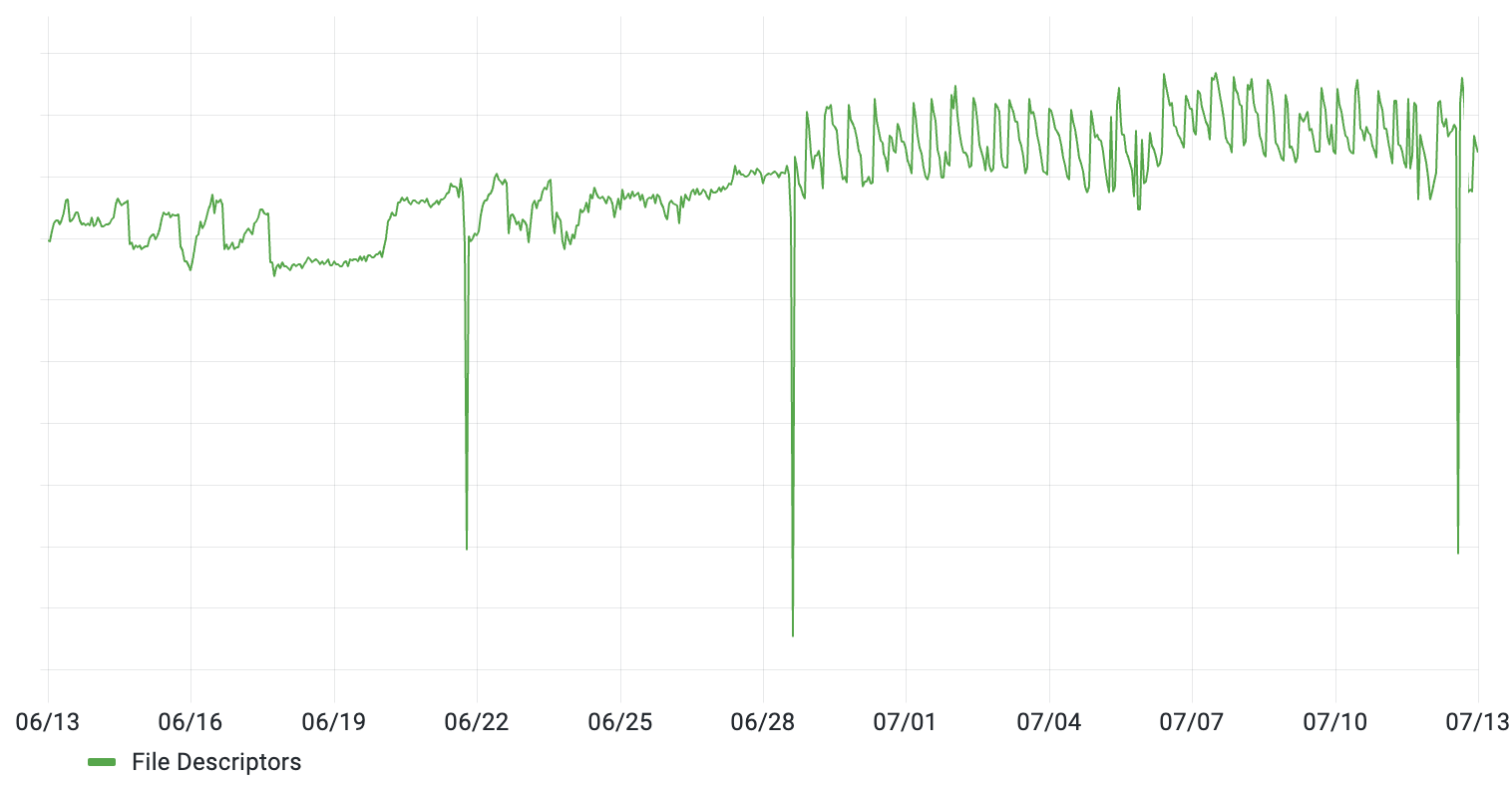
Zooming in, it became apparent that the count was fluctuating very predictably, gradually increasing by ~50 descriptors over a period of 5 minutes before dropping back down:
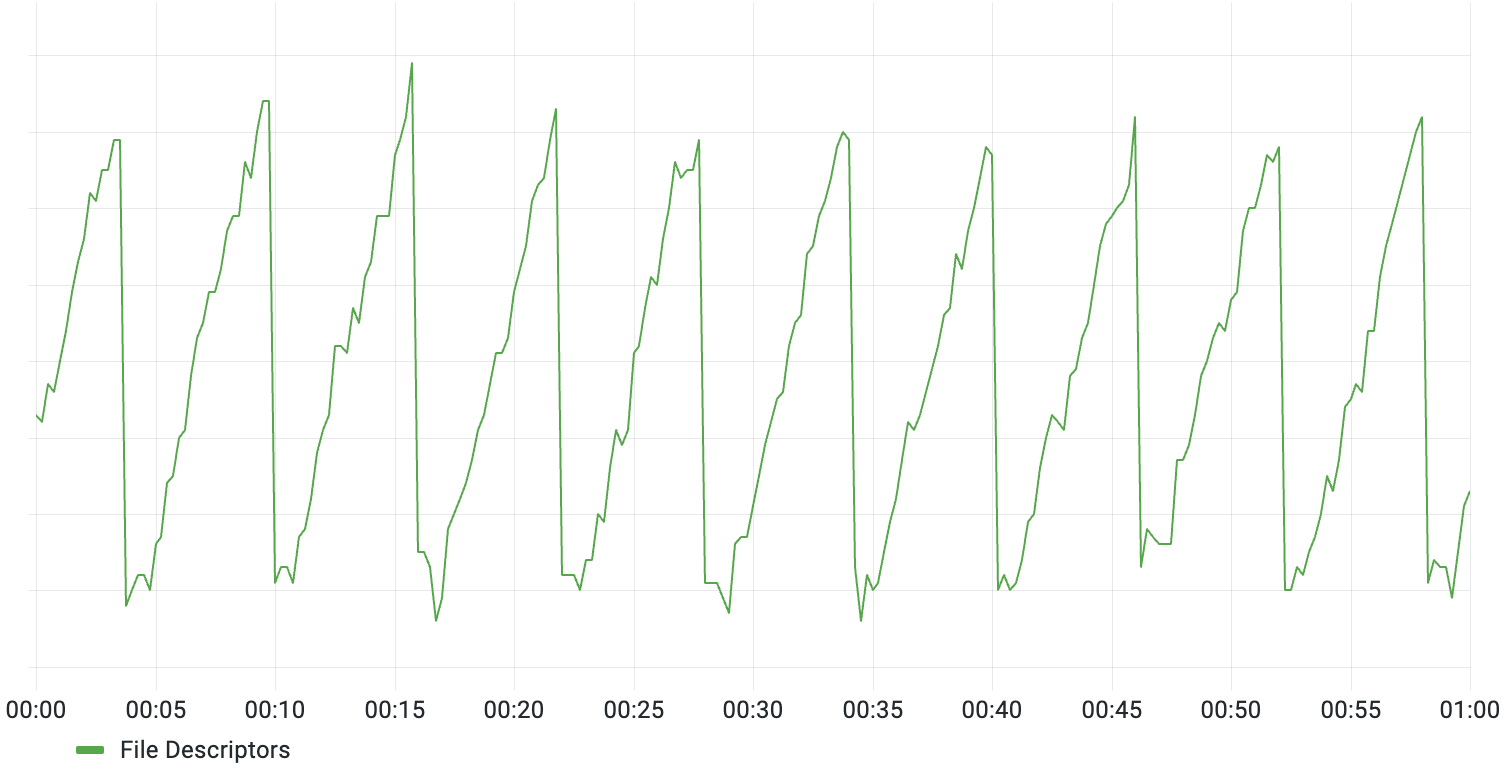
While the absolute change was not alarming, especially since it recovered on its own, there was no obvious trigger for this behavior. The start of this behavior did roughly line up with the release of a new build of the coordination server, but none of the deployed changes seemed related.
I investigated, hoping that maybe I’d learn something. The first thing I did was to see how we were generating this data, in case the problem was somehow a monitoring artifact. The metric is implemented by iterating over /proc/self/fds, which was reasonable enough, thus ruling out that possibility. My next thought was to periodically look at the set of open files (via lsof) and see which ones were closed as part of the big drop every 5 minutes. That yielded a list of the form:
tailcontr 37009 ubuntu 261u sock 0,8 0t0 4128146 protocol: TCPv6
tailcontr 37009 ubuntu 269u sock 0,8 0t0 4144334 protocol: TCPv6
tailcontr 37009 ubuntu 282u sock 0,8 0t0 4096727 protocol: TCPv6
tailcontr 37009 ubuntu 301u sock 0,8 0t0 4085556 protocol: TCPv6
tailcontr 37009 ubuntu 305u sock 0,8 0t0 4084626 protocol: TCPv6
tailcontr 37009 ubuntu 313u sock 0,8 0t0 4151388 protocol: TCPv6
tailcontr 37009 ubuntu 318u sock 0,8 0t0 4088536 protocol: TCPv6
...
While this gave one small clue (the fact that the file descriptors corresponded to TCP connections, as opposed to other file-like things), it didn’t help much. The connections were half-closed, and it was not apparent where they had come from.
I decided to do slightly fancier lsof snapshots and track the lifetime of one of these connections (as identified by its file descriptor, 273 in this case) across the entire 5 minute period:
01:12:17.24 tailcontr 142810 ubuntu 273u IPv6 5725049 0t0 TCP 172.31.10.244:https->1.2.3.4:57666 (ESTABLISHED)
01:13:32.17 tailcontr 142810 ubuntu 273u IPv6 5725049 0t0 TCP 172.31.10.244:https->1.2.3.4:57666 (CLOSE_WAIT)
01:14:03.22 tailcontr 142810 ubuntu 273u sock 0,8 0t0 5725049 protocol: TCPv6
01:16:53.93 (socket is removed)
This showed that it was an inbound connection from a Tailscale client (as opposed to coming from the reverse proxy). Armed with its remote IP and port number, I was able to look in the server logs for any errors relating to that client:
{
"logtail": {
"client_time": "2022-07-19T01:16:33.525315903Z",
"server_time": "2022-07-19T01:16:33.571807282Z"
},
"text": "http: TLS handshake error from 1.2.3.4:57666: acme/autocert: missing certificate\n"
}
A few other connections that I spot-checked all had the same error; thus I was pretty confident that this was related to our use of Let’s Encrypt certificates via the autocert package.
Having uncovered this new piece of information, I looked at the goroutines of the coordination server to see if any were executing autocert code. That showed ever-increasing numbers of goroutines (29, in the output below) waiting to acquire a mutex:
29 @ 0x43ac56 0x44b7f3 0x44b7cd 0x467045 0x7ab0a5 0x7ab07f 0x7aa2c9 0x61c1c2 0x64bff4 0x64a893 0x6453f0 0x62600f 0x6e85d3 0x6e85d4 0x46b0e1
# 0x467044 sync.runtime_SemacquireMutex+0x24 runtime/sema.go:71
# 0x7ab0a4 sync.(*RWMutex).RLock+0x164 sync/rwmutex.go:63
# 0x7ab07e golang.org/x/crypto/acme/autocert.(*Manager).cert+0x13e golang.org/x/crypto@v0.0.0-20220518034528-6f7dac969898/acme/autocert/autocert.go:444
# 0x7aa2c8 golang.org/x/crypto/acme/autocert.(*Manager).GetCertificate+0x448 golang.org/x/crypto@v0.0.0-20220518034528-6f7dac969898/acme/autocert/autocert.go:299
# 0x61c1c1 crypto/tls.(*Config).getCertificate+0x41 crypto/tls/common.go:1064
# 0x64bff3 crypto/tls.(*serverHandshakeStateTLS13).pickCertificate+0x353 crypto/tls/handshake_server_tls13.go:363
# 0x64a892 crypto/tls.(*serverHandshakeStateTLS13).handshake+0x52 crypto/tls/handshake_server_tls13.go:55
# 0x6453ef crypto/tls.(*Conn).serverHandshake+0xcf crypto/tls/handshake_server.go:54
# 0x62600e crypto/tls.(*Conn).handshakeContext+0x32e crypto/tls/conn.go:1460
# 0x6e85d2 crypto/tls.(*Conn).HandshakeContext+0xdd2 crypto/tls/conn.go:1403
# 0x6e85d3 net/http.(*conn).serve+0xdd3
That mutex was being held by a goroutine that appeared to be in a retry loop:
1 @ 0x43ac56 0x44a712 0x796374 0x796d92 0x799ef9 0x7ad869 0x7ad4e5 0x7ac505 0x7aa38d 0x61c1c2 0x64bff4 0x64a893 0x6453f0 0x62600f 0x6e85d3 0x6e85d4 0x46b0e1
# 0x796373 golang.org/x/crypto/acme.(*retryTimer).backoff+0x113 golang.org/x/crypto@v0.0.0-20220518034528-6f7dac969898/acme/http.go:45
# 0x796d91 golang.org/x/crypto/acme.(*Client).post+0x191 golang.org/x/crypto@v0.0.0-20220518034528-6f7dac969898/acme/http.go:198
# 0x799ef8 golang.org/x/crypto/acme.(*Client).AuthorizeOrder+0x298 golang.org/x/crypto@v0.0.0-20220518034528-6f7dac969898/acme/rfc8555.go:228
# 0x7ad868 golang.org/x/crypto/acme/autocert.(*Manager).verifyRFC+0x108 golang.org/x/crypto@v0.0.0-20220518034528-6f7dac969898/acme/autocert/autocert.go:700
# 0x7ad4e4 golang.org/x/crypto/acme/autocert.(*Manager).authorizedCert+0x1c4 golang.org/x/crypto@v0.0.0-20220518034528-6f7dac969898/acme/autocert/autocert.go:673
# 0x7ac504 golang.org/x/crypto/acme/autocert.(*Manager).createCert+0x2c4 golang.org/x/crypto@v0.0.0-20220518034528-6f7dac969898/acme/autocert/autocert.go:588
# 0x7aa38c golang.org/x/crypto/acme/autocert.(*Manager).GetCertificate+0x50c golang.org/x/crypto@v0.0.0-20220518034528-6f7dac969898/acme/autocert/autocert.go:311
# 0x61c1c1 crypto/tls.(*Config).getCertificate+0x41 crypto/tls/common.go:1064
# 0x64bff3 crypto/tls.(*serverHandshakeStateTLS13).pickCertificate+0x353 crypto/tls/handshake_server_tls13.go:363
# 0x64a892 crypto/tls.(*serverHandshakeStateTLS13).handshake+0x52 crypto/tls/handshake_server_tls13.go:55
# 0x6453ef crypto/tls.(*Conn).serverHandshake+0xcf crypto/tls/handshake_server.go:54
# 0x62600e crypto/tls.(*Conn).handshakeContext+0x32e crypto/tls/conn.go:1460
# 0x6e85d2 crypto/tls.(*Conn).HandshakeContext+0xdd2 crypto/tls/conn.go:1403
# 0x6e85d3 net/http.(*conn).serve+0xdd3 net/http/server.go:1848
The goroutine in the retry loop used a context with a 5-minute timeout, which explained the periodic nature of the problem — it would eventually give up, and only then would all the piled-up goroutines/connections get a chance to run (and fail quickly).
The question then became: What certificate were we trying to fetch? After adding some logging and then redeploying the server, the answer turned out to be login.tailscale.com, which (perhaps unsurprisingly) was the domain name of the coordination server. However, that domain was now being served by the reverse proxies; thus the certificate requests should never have made it that far. The coordination server would end up starting the Let’s Encrypt challenge process, but when Let’s Encrypt attempted to complete it, it would instead reach the reverse proxies, which had no knowledge of this in-progress challenge.
What led to these certificate requests? Our best guess was that some users had hardcoded the DNS entry for login.tailscale.com to the coordination server’s IP, and therefore they had never picked up the DNS change from back in mid-May, which redirected the traffic to the reverse proxies. The autocert package can be configured to only allow certain hosts’ certificates to be looked up, and we still had login.tailscale.com on the list (we had never dropped it after the migration). After we removed it, the spikes disappeared (the users were unable to connect the control server either way, but it would now fail immediately instead of waiting for the 5-minute timeout):
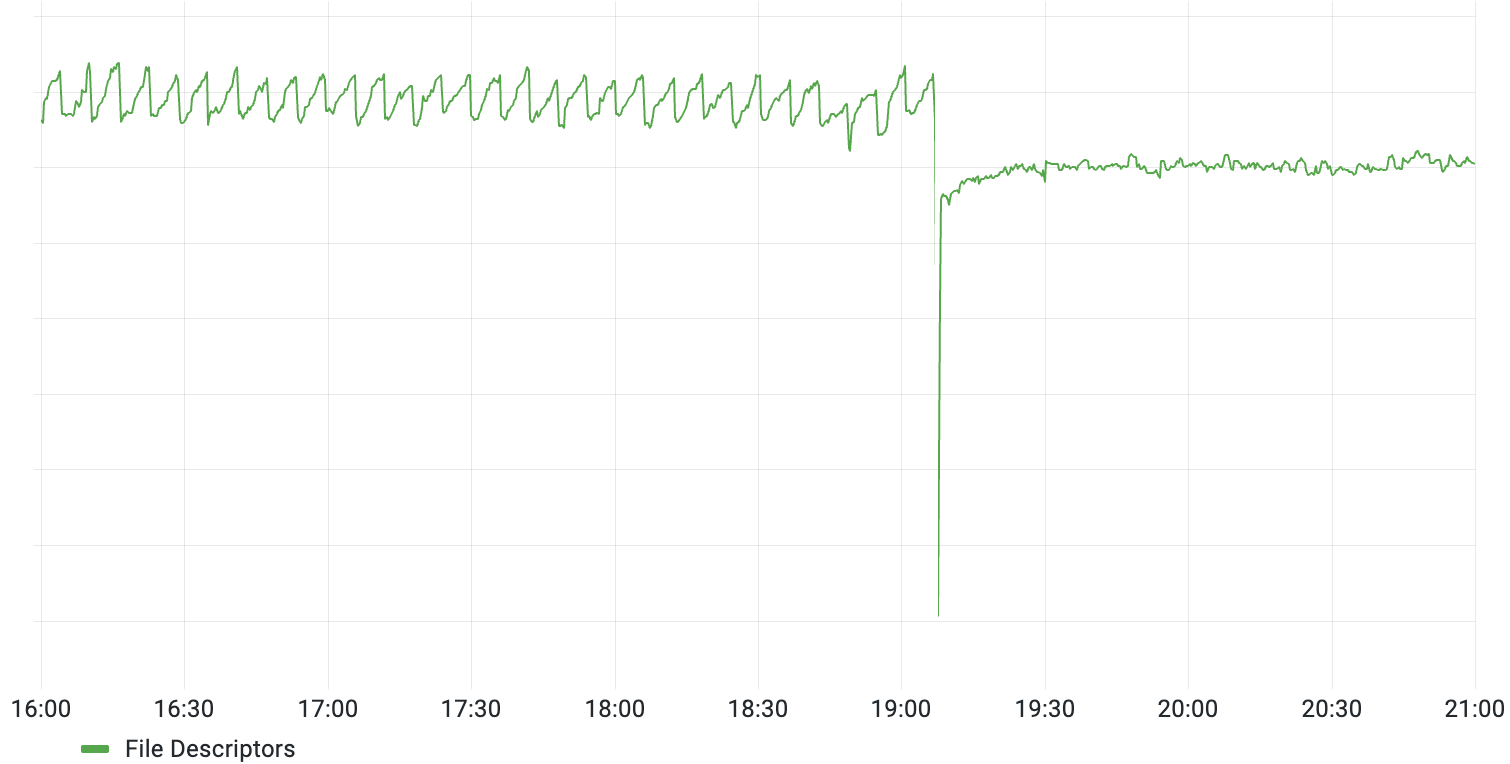
As for why this started to happen on June 28th (as opposed to immediately after the switchover to the reverse proxies), our best guess is that the previous Let’s Encrypt-issued certificates that we were using expired shortly before (on June 26th), and the deployment on June 28th cleared a cache, forcing them to be re-requested.
This investigation reinforced the breadth of interestingly (for some values of “interesting”) configured clients that Tailscale (or any other service) has to deal with. While this was not the gnarliest bug ever, it was satisfying to keep accumulating breadcrumbs that explained more and more behaviors (e.g. the 5 minute timeout in the autocert library). And by closing it out, we were able to continue on our quest to make things just work.
 Mihai Parparita
Mihai Parparita




