This post originally appeared on the personal site of Lee Briggs, Director of Solutions Engineering at Tailscale. We repost it here with Briggs' permission (and some edits). We value Tailscalars’ opinions, though they may not represent those of Tailscale itself.
An easy, realistic model for MCP connectivity

You can’t escape it. Everywhere you turn in the tech ecosystem, AI is there.
Whether you’re an AI skeptic or an AI convert, you almost certainly understand how explosive its impact on the tech ecosystem has been, and how fast everything is moving right now.
I’ll keep my personal opinions about AI out of this blog (mostly), but I’ve been staying very familiar with the Model Context Protocol (MCP) for a few reasons. The primary one being that it seems absolutely terrifying in ways I can’t really comprehend.
Many of the security lessons we’ve learned over the years seem to have been overlooked in MCP’s rapid development. “Protect your data, it is what’s unique to you!” was the battle cry of every tech-oriented person for most of my career. I’m old enough to remember when Cambridge Analytica was raked over the coals because it weaponised our social media data. A few years later, we now seem quite content with the idea of letting Large Language Models (LLMs) slurp up mountains of our private data to train their word-guessers.
I’m being as glib as I always am on my blog, but in all seriousness, MCP has a problem—you want to get your data into an LLM, but you don’t want everyone else to be able to see it.
A quick history of the MCP evolution
At its core, MCP is a funnel. How do I get local information—or information that isn’t crawlable on the public internet, at least—into an LLM, so that LLM can analyse it? Anthropic defined the MPC spec to help you do just that. In its infancy, the trick was simple: run a local server that speaks JSON, so a local client can call it and pipe data into the LLM.
The initial version of the spec seemed destined for local connectivity. The servers were designed to be accessed over a stdio transport, which you’d run locally and then connect to with an MCP client, like Claude Desktop. Stdio is just “standard input and output streams,” and isn’t at all designed to be called remotely, so generally your data is pretty safe. It’s really not easy to intentionally expose your data to the big scary world this way.
Running a stdio-based MCP servers was pretty straightforward. Most MCP servers are written in Typescript or Python. To configure them, you insert the commands that you use to start the MCP server into your MCP client, and have it execute it on startup—easy.
In Claude Desktop for example, here’s how you’d run a filesystem MCP so Claude can analyse your local filesystem:
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/Users/username/Desktop",
"/Users/username/Downloads"
]
}
}
}Pretty straightforward if you can, you know, easily write JSON and understand what the hell npx is. Obviously, for non-technical users, this looks like a magical incantation, but that’s okay—MCP is early-stage stuff at this point.
As things have progressed (very, very quickly, I might add), it’s become obvious to people that eventually, you will want to be able to run these MCP servers somewhere else, other than on your local machine. Various companies have sprung up around this, with varying degrees of success and questionable security tactics.
So the spec evolved to meet these needs, and the next iteration introduced a mechanism to access MCP servers remotely, which became Server Side Events (SSE).
You can see on SSE’s Transports page suggestions for how make sure this remote access doesn’t go badly for you. One version reads:
Security Warning: DNS Rebinding Attacks SSE transports can be vulnerable to DNS rebinding attacks if not properly secured. To prevent this:
- Always validate Origin headers on incoming SSE connections to ensure they come from expected sources
- Avoid binding servers to all network interfaces (0.0.0.0) when running locally - bind only to localhost (127.0.0.1) instead
- Implement proper authentication for all SSE connections
- Without these protections, attackers could use DNS rebinding to interact with local MCP servers from remote websites.
SSE started to take off, despite these warnings on the server side. Despite the pace of protocol and spec innovation, MCP clients were surprisingly slow to introduce support for this. At the time of writing, I still can’t find a client that is broadly used that will allow you to connect easily to an SSE server.
So we started to see a new type of tool appear: the proxy. It would proxy requests from stdio clients into SSE events, allowing people to run those SSE servers remotely.
Finally, the most recent thing to try has been to completely rework SSE (after only five months, by my count!) and switch to Streamable HTTP as an alternative. This might just set the land speed record for a protocol deprecation, but still—an evolution, nonetheless.
And yet, there's still a problem
As all this change has happened, I’ve been watching it and thinking to myself, “Well, okay, but this is still a security nightmare”. There are obviously things changing here, and there’s intent to fix it. But take another look at the Streamable HTTP warnings and spec. There is no published document (as of this blog post’s writing) that introduces any sort of authentication to the protocol. It has been drafted, and follows a fairly typical pattern of late: “Let’s slap some OAuth on top of it and call it good”.
Personally, that doesn’t make me particularly happy, because I think OAuth is really confusing and easy to screw up. Secondly, you still have a communication problem. I don’t care how much authentication you put on top of something—if there’s particularly sensitive data behind something, I still don’t want it hanging around on the internet. If you do feel okay with this, I presume all your databases are on the internet as well, but it’s okay because they have passwords on them. Right?
So, this got me thinking. I work for Tailscale. Tailscale’s really quite good at protecting your data and connecting things together. How can we improve this situation?
My first MCP server
As things were evolving, I wrote a little MCP server for the Tailscale API that allows you to query a few things, primarily to try and understand the protocol and see what useful things we could do. I stuck with stdio and then introduced SSE, but was pretty unhappy with how things looked at that point, so left it at that.
However, when Steamable HTTP docs were published a few weeks ago, I realised there was an opportunity to think differently about the security model, to make it a little more robust, and considerably more private.
You can get some of the benefits of Tailscale with Streamable HTTP by just having Tailscale on both ends of the equation. Install Tailscale on your local machine, spin up another server and install Tailscale on it before configuring your Streamable HTTP server, then configure your MCP client to run an MCP proxy (of which there many, such as sparfenyuk/mcp-proxy or, if you prefer Typescript, punkpye/mcp-proxy). When you configure the proxy, set your endpoint to the remote Tailscale address and the port/url your MCP server is listening on, and you’re golden.
This is a massive improvement over the “Run it on the internet model with OAuth” tactic, because now you don’t have to run the damn thing on the public internet, which should be fairly obvious. I was going to go with this approach, but then I had another idea. What if we could use Tailscale’s application awareness to improve the security model even more?
So I did two things:
- I wrote a little MCP proxy in Go that forwards Tailscale’s headers, like
X-Tailscale-User, to the remote HTTP MCP server - I updated my Tailscale MCP server to support reading Tailscale’s grants mechanism to determine what that Tailscale user is allowed to do.
A proper security model in action
So how does this look? Well, I can run my Tailscale MCP server on a remote machine. I spun up a VM in digital ocean and fired it up:
curl -L https://github.com/jaxxstorm/tailscale-mcp/releases/download/v0.0.3/tailscale-mcp-v0.0.3-li
nux-amd64.tar.gz | tar -xzf -
TS_AUTHKEY=<your-auth-key> ./tailscale-mcp --tailnet=<your-tailnet> --api-key=<tailscale-api-key>
Some output logs:
4:48:37 INFO tailscale-mcp/main.go:265 Starting ts-mcp {"version": "0.0.3", "tailnet": "lbrlabs.com", "hostname": "ts-mcp", "port": 8080, "debug": false, "stdio": false}
2025/06/09 14:48:37 tsnet running state path /root/.config/tsnet-tailscale-mcp/tailscaled.state
2025/06/09 14:48:37 tsnet starting with hostname "ts-mcp", varRoot "/root/.config/tsnet-tailscale-mcp"
2025/06/09 14:48:37 Authkey is set; but state is NoState. Ignoring authkey. Re-run with TSNET_FORCE_LOGIN=1 to force use of authkey.
14:48:37 INFO tailscale-mcp/main.go:558 Serving MCP via Tailscale {"address": ":8080"}
14:48:37 INFO tailscale-mcp/main.go:586 Serving MCP locally {"address": "127.0.0.1:8080"}
2025/06/09 14:48:42 AuthLoop: state is Running; doneNow, I just need to configure my MCP client (in my case, Claude Desktop) to run my MCP proxy locally.
{
"mcpServers": {
"tailscale": {
"command": "/usr/local/bin/tailscale-mcp-proxy",
"args": ["--server", "http://ts-mcp:8080/mcp"]
}
}
}I need Tailscale running on my machine so they can communicate with each other and capture the information on who I am.
tailscale status
100.84.243.110 lbr-macbook-pro mail@ macOS -
100.72.57.77 lbr-iphone mail@ iOS offline
100.81.81.4 lon-derp1 tagged-devices linux -
100.105.3.74 sea-derp1 tagged-devices linux -
100.66.15.114 ts-mcp mail@ linux idle; offline, tx 52624 rx 72604Now, I can fire up Claude Desktop and ask it questions about my Tailnet:

But wait, it’s telling me I don’t have permission? If we look at the MCP server’s logs, we can see I don’t have the right access to run the query:
15:17:08 INFO tailscale-mcp/main.go:159 No MCP capabilities found
15:17:08 WARN tailscale-mcp/main.go:172 No MCP capabilities found {"user": "mail@lbrlabs.com"}The reason for this is that my Tailscale MCP server is going to use Tailscale’s grants to determine which tools I’m allowed to call. So lets add a grant to my Tailscale ACL to indicate I can call all tools:
{
"src": ["autogroup:admin"],
"dst": ["100.66.15.114"], // the address of my Tailscale MCP, I could also use tags
"ip": ["tcp:8080"],
"app": {
"jaxxstorm.com/cap/mcp": [{
"tools": ["*"], // I can call all tools
"resources": ["*"], // I can call all resources
}],
},
},Now, let’s try that query again!
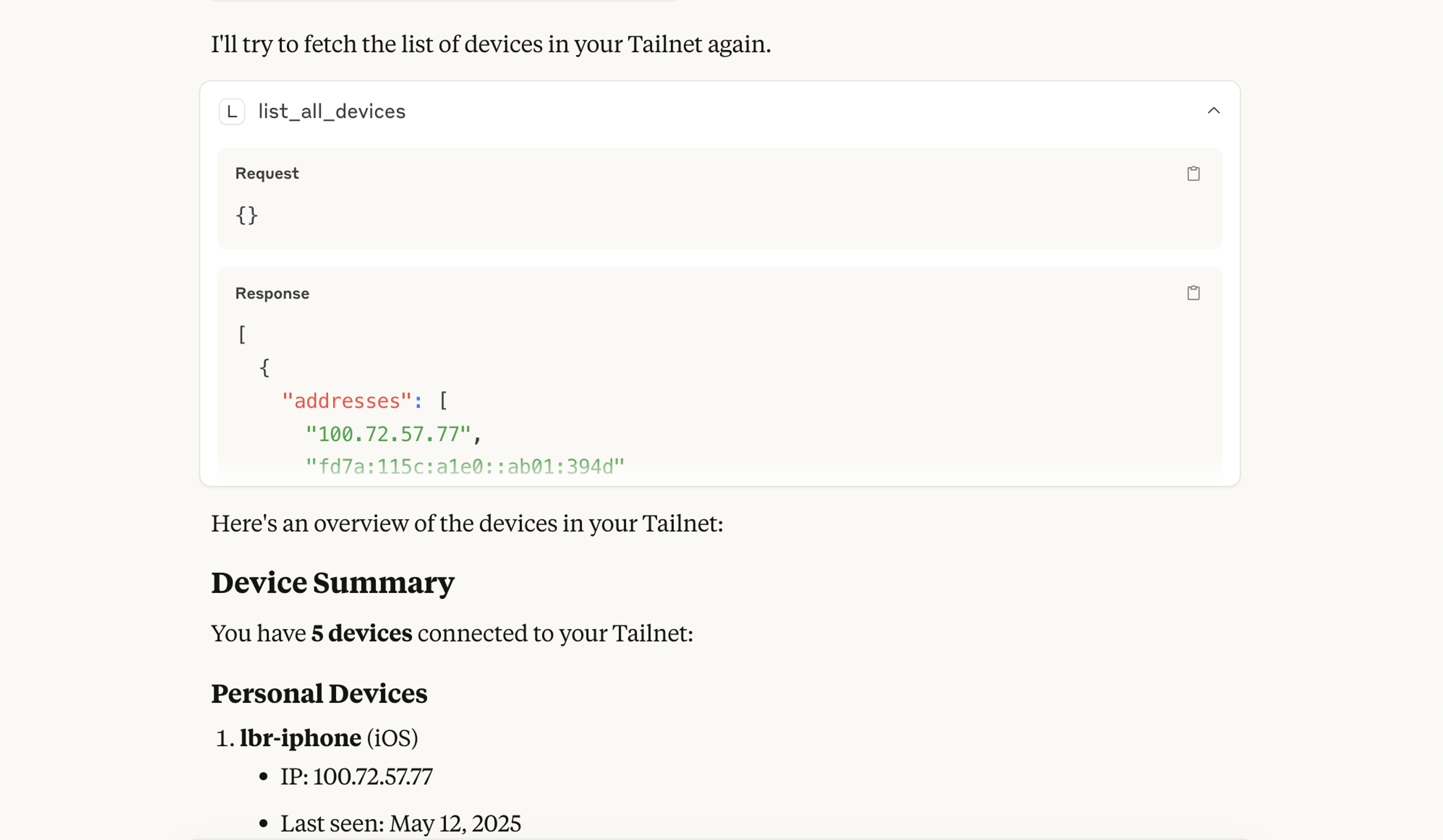
Success!
The caveats
This is all well and good, but what are some of the considerations to this approach?
As it stands, tsnet (used to build the Tailscale-ready MCP proxy) is only really usable for Go servers, so you’d need to write your MCP server in Go, for which there is no official SDK. Most MCP servers are written in Typescript or Python; to each their own.
Note: Tailscale does have a proof of concept C-based library which could be used for Python and Typescript based MCP servers, and if you’re interested in using it, you should contact us at Tailscale by posting on Reddit
The other side of this, of course, is that only local clients can implement these proxies. Anthropic supports calling remote MCP servers on its enterprise plans, but it expects them to be on the public internet. I would personally love the idea of being able to connect from your Claude team to your Tailnet (imagine just giving Claude your Tailscale OAuth credentials and it provisions a private network for your MCP connections!) but I’ll need someone from Anthropic to implement that.
I’m also personally a huge fan of this Tailscale application model of permissions and capabilities. But I suspect the first detraction will be, “We want these standards to be open, not have Tailscale in the middle of them!” Which I totally get.
The code
Finally, and to close this post down, if you want to try any of this yourself, you can find all the code for the MCP server here and the MCP proxy here. I hope this inspires you to get something important off the public internet!
Hypocrisy?
You’ll recall at the beginning of this post, I was lamenting the idea that we’re going to let LLMs hoover up all our data. Yet here I am, enthusiastically writing MCP servers to better connect them.
I suppose that’s the thing about technology: You can either participate in shaping how it develops, or you can stand on the sidelines complaining about how everyone else is doing it wrong. I’ve chosen to participate, even if it means being part of a system I have mixed feelings about.
The best I can do is try to build a secure version of something that’s developing all around me. Maybe that makes me a hypocrite, but at least I’m a hypocrite that’s thinking about protecting your data from the scary internet, so that only the LLM can access it. That makes it better, right?
Share
Author
 Lee Briggs
Lee BriggsLoading...





